I was reading into this article which I found on a post by @anon56682183 in the Forum : Chris Grieser – Researcher in Sociology
The fourth step : “4. Extracting Annotations/Notes From PDFs” mentions a lot many PDF annotation extractors. Many of them I have had tried in the past (In fact, all), but couldn’t find the best option out of them. While Zotero option was too clumsy for me who is not into Research Paper reading, but rather Books and PDFs which no requirement to cite them, the other options missed the key feature of linking the PDF page. Obsidian Annotator does have this feature, but as it is mentioned in the article as well, it can only be used to annotate a pdf inside of Obsidian Desktop.
All in all, back in May I ended up writing my own code for the extraction of annotations and even the drawings or images in a markdown file with a template or layout of my own liking. It was very very crude as I was coding for the first time, but worked fine. I still couldn’t find a way to insert a link to the PDF page for it to open in the default browser using URI or something (I don’t know how it works)(I can put the page number of the annotation in text though). Otherwise it was quite easy, plus it has the ability to pull images or diagrams that are enclosed withing a rectangle 
I will try to show what my code does.
This is the annotated test file:
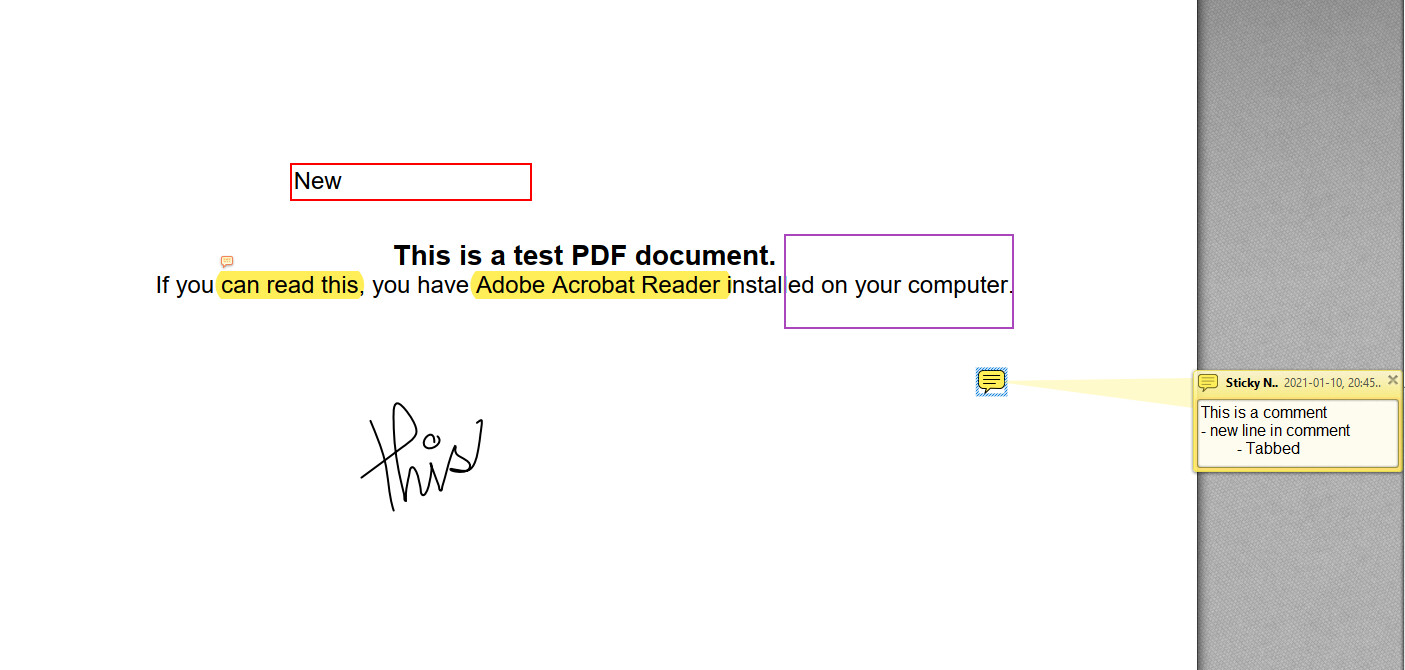
This is what the extracted note looks like: (on a theme Yin and Yang)

NOTE
- The sequence needs to be modified, that is from Left to Right, Top to Down. (That was implemented later on, I just don’t remember which iteration was it, lol)
- The flow in the following way:
- PDFs to be extracted are kept in a folder with the python code file.
- Run the code, and it creates separate folders for each PDF with its name, and contains one .md file and all the associated extracted images.
- The images are named based on two criteria - commented rectangle or random.
- The first line of the comment of the Rectangle becomes the name of the image file.
- Else, a random incrementing file name is created.
- The naming process can be made better later on too, I think
- Page numbers are extracted, but they are commented here. It can be placed anywhere of course.
THE PROBLEM IS, I NEVER USED IT AGAIN.
The simple reason to it was, inability to detect the sentence on which there was a highlight. Say there is a sentence This is a sentence, and **this is the annotated part**, my code will simply extract this is the annotated part while ideally it should extract the whole sentence. I have seen native pdf softwares to be doing this. Since, I don’t highlight everything, I just highlight the part I need, but then the context is missing. I don’t now if someone can relate to me, or I am really bad at explaining it
What are your ways to handling your highlights if you aren’t a researcher and don’t really highlight the whole sentence from start to the end?
- Couldn’t there be a simple plugin to import .fdf exports?
- Extraction part is easy, if I could do it. If someone could work on something like this with the page link to open in the default software, it would be great
