Brute force on feature
Here is an attempt at brute forcing based on the last word of the feature description. This should be possible to use directly on the two example files you gave, but I reckon you should have a better way of selecting which files to use somehow. The query uses the file names hard coded, and is more a proof of concept rather than a viable solution.
Base query
The basic idea is to flatten out the feature into its separate feature description, pick out the last word, and then group the results based on this last word. The base query then looks something like:
```dataview
TABLE rows.aFeature, rows.file.name
WHERE folder = this.folder AND feature
FLATTEN feature as aFeature
FLATTEN slice(split(aFeature, " "), -1) as lastWord
GROUP BY lastWord
```
Explanation on base query
The first FLATTEN expands the list we’re working with by flattening the features listed in feature into a single field, aFeature, with one row per feature. If this doesn’t make sence, try the query without the last two lines , and use aFeature and file.name in the column lists.
The second FLATTEN does two operations. It splits the feature based on the space character into a list, so that 4 GB RAM becomes a list of 4, GB, RAM. The slice operation picks the last element, -1, of this list, and stores this word into lastWord.
Finally we do a GROUP BY lastWord which groups together rows where lastWord is equal. Now all previous fields are stored into the rows object. So aFeature becomes the list rows.aFeature, and so on.
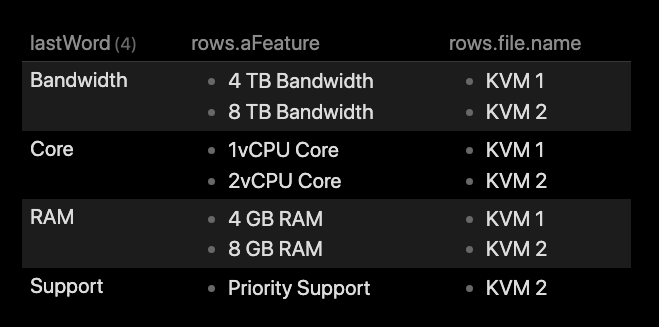
If you run this in a folder holding the files KVM 1 and KVM 2 as example files you get this output:
As can be seen this lists the various features in separate rows, but it’s kind of hard to differentiate which feature belongs to which files, as you need to cross-reference two columns with their rows. Not good…
Filtering out per file
Using the previous query as the base input, we can manipulate the rows object to pick out a given file and display only that in a given column. One variant of this could then look like:
```dataview
TABLE KVM1, KVM2
WHERE folder = this.folder AND feature
FLATTEN feature as aFeature
FLATTEN slice(split(aFeature, " "), -1) as lastWord
GROUP BY lastWord as Feature
FLATTEN filter(rows, (r) => r.file.name = "KVM 1")[0].aFeature as KVM1
FLATTEN filter(rows, (r) => r.file.name = "KVM 2")[0].aFeature as KVM2
```
Explanation of the filtering
In this query we started with the base query, but after we’ve grouped the result, we’re going to filter out results related to a specific file. To do this we use the filter() command on the entire rows object, and for each element of that list, we pick one row (r) => , and checks the file name of that particular row of the list, through doing r.file.name = "KVM 1".
The filtering should give us a list of exactly one element, so we use [0] to pick the first (and supposedly only) element of that list, and furthermore we pick the aFeature element from this row. This is stored in a unique file name related field, so that we use that as a column in the first line of the query.
The effect of all this mumble-jumble is the following output:
An even uglier variant…
Here is a query which is getting hairy, where you can provide the filename in a list:
```dataview
TABLE File1 as first, File2 as second
WHERE folder = this.folder AND feature
FLATTEN flat(list(feature, file.name + " Filename")) as aFeature
FLATTEN slice(split(aFeature, " "), -1) as lastWord
GROUP BY lastWord as Feature
FLATTEN list(list("KVM 1", "KVM 2")) as filelist
FLATTEN regexreplace(filter(rows, (r) => r.file.name = filelist[0])[0].aFeature, " Filename$", "") as File1
FLATTEN regexreplace(filter(rows, (r) => r.file.name = filelist[1])[0].aFeature, " Filename$", "") as File2
SORT choice(contains(Feature, "Filename"), -1, Feature)
```
Which produces an output like:
Hopefully, you understand how you can expand upon this to compare more than two files, by extending the list, and by copy-pasting one of the latter FLATTEN lines, and replacing filelist[1] with filelist[2], and File2 with File3, and so on…
This query “extends” the feature list with the filenames, as we can’t have dynamic titles for the columns, AFAIK, and since we added this to the feature list, we also needs to do some extra cleanup to remove the Filename extension of that feature… And we also needs to extend the query with a little sorting hack to show the filename at the top. Not my cleanest query, but it gets the job done to some extent. 
I’ve not written the queries for the more specific field variants, (using featureCore or featureRAM and so forth), which most likely can be made dynamic. It’s a little more work to do those queries, and you’ve not responded whether that’s a feasible way forward for you, and whether you’ll be able to maintain such a query.