My issue is somewhat similar to the following: Using multiple tags on a single note with Dataview
What I’m trying to do
I have come across this issue multiple times in the past, I would like to be able to query a specific line of inline variables within a note and have them query separately in dataview, even if the same inline variables are used somewhere else.
Example:
Below is my daily note format, I use daily notes as the brain dump with a bunch of inline fields and then want to be able filter out specific information later using dataview. This works incredibly well using TASKS (because they’re little contained packages), but not well using anything else by the looks of it. I really want to be able to query bullet points as well as I can for tasks.
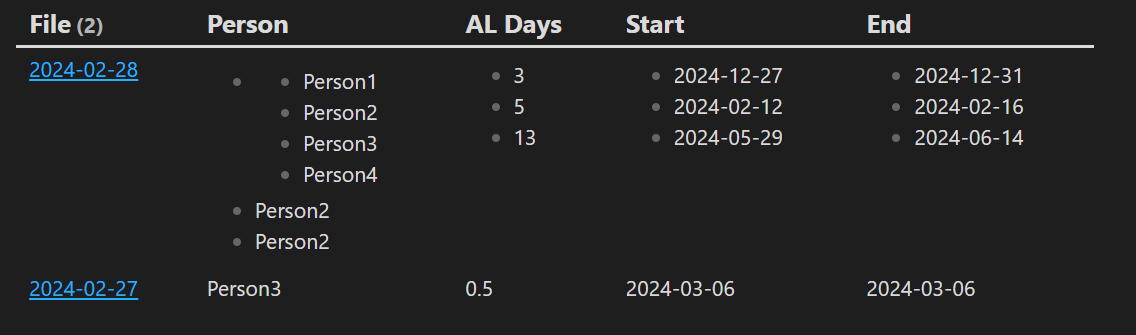
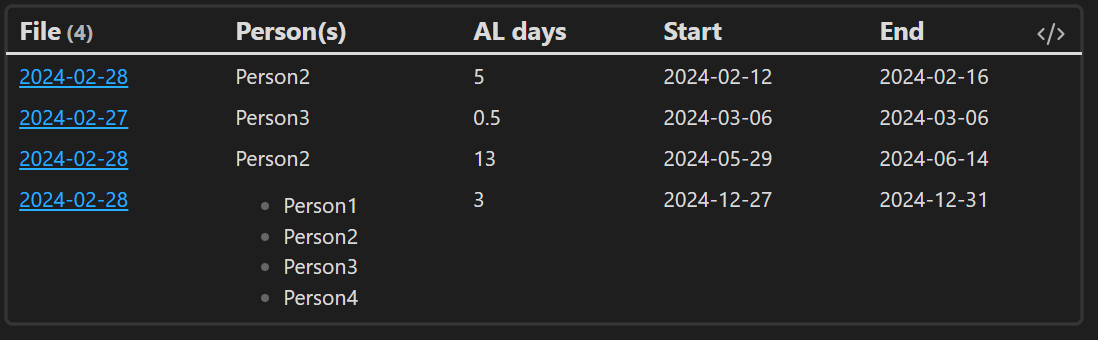
The example that i came across is that I want to run an annual leave log for a set of people, as my daily notes is my centre, I input all the leave so far in the daily note under different bullets.
When I try and query them in dataview, it can’t separate anything within the same note.
---
starttime: 08:55
lunchtime: 30
finishtime:
othertime:
tags:
- DailyNote
---
#### (date:: 2024-02-28)
---
# Log
- [ ] Task example 1 || [duedate:: ] || [project:: ] || [topic:: ] || [priority:: ] || (person:: Person1) || (type:: work) || (date:: ) || (state:: ) ||
- [person:: "Person1", "Person2", "Person3", "Person4"] || [leavedays:: 3] || [leavestart:: 2024-12-27] || [leaveend:: 2024-12-31]
- [person:: Person2] || [leavedays:: 5] || [leavestart:: 2024-02-12] || [leaveend:: 2024-02-16]
- [person:: Person2] || [leavedays:: 13] || [leavestart:: 2024-05-29] || [leaveend:: 2024-06-14]