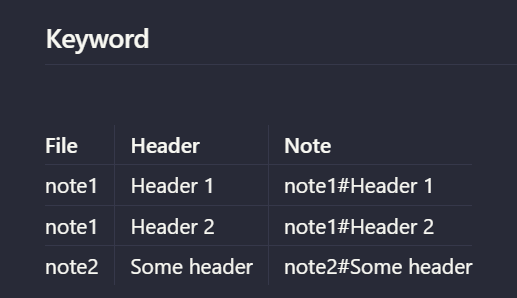
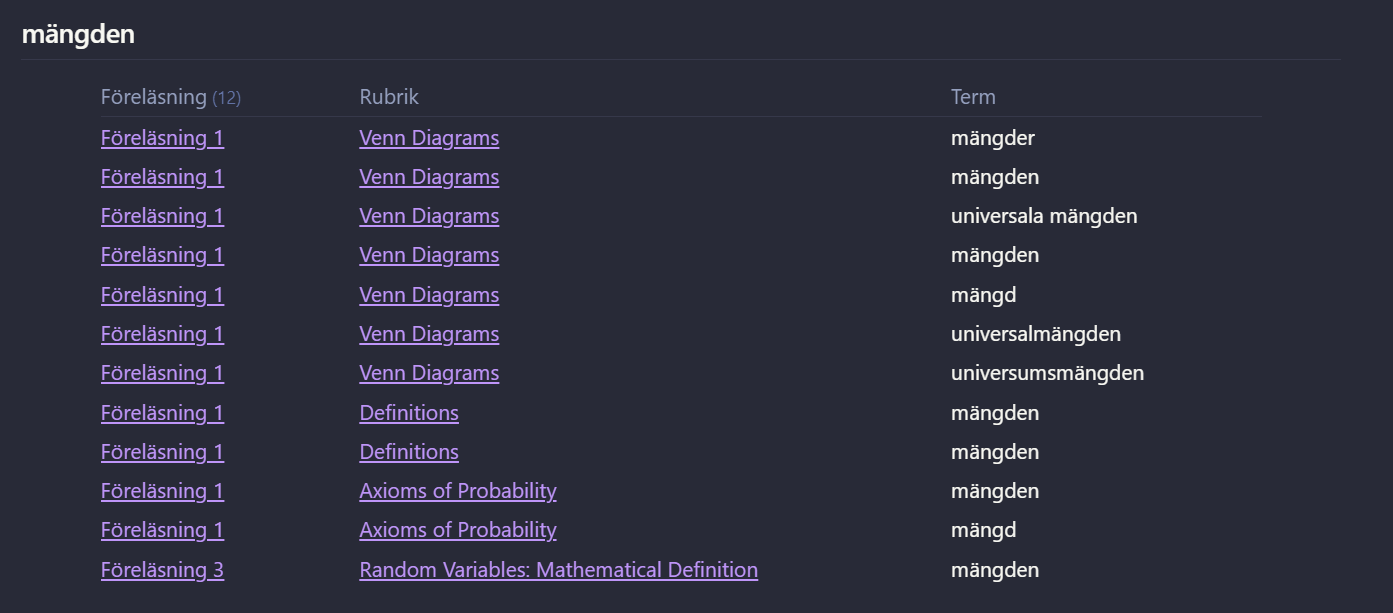
I’m trying to create a Dataview table that lists each internal link (e.g., [[keyword]]) once per header, per file.
For example, say I have a note at Folder/to/note/note1.md with:
# Header 1
Random [[keyword]] with clear purpose.
# Header 2
Another [[keyword]] with equally clear purpose.
And another note note2.md in the same folder also contains the same [[keyword]] inside one of its headers.
I want to generate a table (in a separate note, located at Folder/to/note/keywords/keyword.md) that shows each file and header that contains [[keyword]], with a link to the header, like:
Hey holroy, I stumbled upon many of your posts in my search. Did try mana dataviewjs code block approaches as well, but having basically no javacode knowledge is making me scratch my already balded head. ChatGPT also couldn’t help me