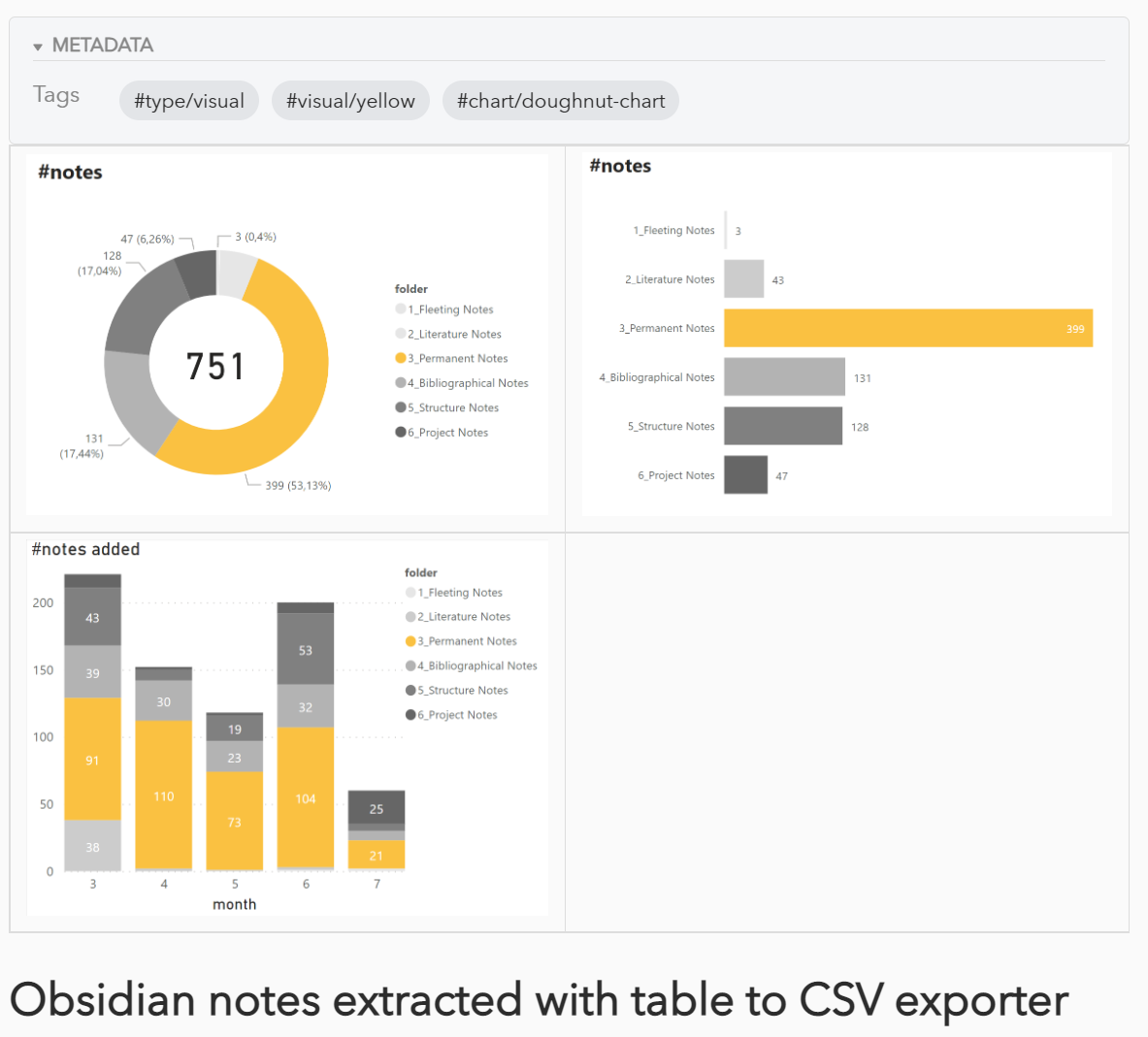
Hi, I’m very surprised as an average user ، Why is there no news of data analysis in Obsidian ?
It’s really surprising that all these different topics are all just about viewing information
The biggest achievement of Obsidian is the ( data view ) plugin
It is unfortunate that it is not possible to analyze information for obsidian, that is, obsidian did not allow mathematics to actually enter the program, and we all know that without weighting and mathematics, there is no analysis.
Weighing information, combining information, pruning information, deleting information, albeit semi-intelligently in obsidian allows us to name the program literally (second brain)
Our brain does not just show data, it analyzes it, and as long as the obsidian does not have the power to analyze information, it can not claim our second brain.
And it does not seem to be a difficult task, it is strange that no action has been taken so far
I suppose one reason for that could be that people build their vaults in different ways, so there may not be one general approach for analysing vaults.
However, I do think basic summary statistics could be done in the app, for example: how many words are there in my notes, how many notes are in my vault, which notes have I not edited recently, etc.? The ‘decision science’ part you allude to will need a lot of finesse, but is clearly valuable. When I’ve searched online for data-driven approaches to knowledge management via graphs (like you can get with Obsidian), I don’t find much useful content.
I’ve built a Python package to analyse my Obsidian.md vaults (obsidiantools). It’s been very useful for my knowledge management, although if I ask myself a question like “what are the most central / important notes in my vault?”, there isn’t a clear answer to that. I have implemented multiple centrality algorithms in Python and they give different results. I haven’t used Map of Content (MOC) or Zettelkasten in my vaults, but if I structured my vaults on those principles then the ‘central’ notes would be different, as the philosophy of knowledge management is different.
There’s a lot of content in the community about knowledge management approaches, but there’s little on data-driven approaches for scaling the decision science. This is definitely an interesting area to me so it’d be cool to bounce ideas with people who want to explore what analytics could be done on vaults.
After researching machine learning software, I came to the conclusion that data mining and text mining are a subset of machine learning that can analyze data, but unfortunately the data, most of which are based on numbers and formulas. , And applies to a series of rules and parameters of physics and chemistry such as meteorological forecasting, analysis of student score data and so on. But we humans are always analyzing and calculating the outside world and the inside world, our emotions are formed entirely by mathematical calculations, the decisions we make are made entirely by mathematical calculations, and there is no tool for examining the nature of the human mind. . There is no software to analyze it. . Of course, except for the brain itself. While we all know that the concepts created by the magnificent human brain are entirely based on mathematics and numbers, and so far only the brain itself can analyze these concepts relatively. What happens if we leave this analysis of concepts and meaning to computers to help us? Our world will change, our brains sometimes make mistakes in analyzing concepts and meanings due to the nature of habit, but computers that have received this training will not. The result is that we do not have data analysis in obsidian, at best we can only write down, label and search for concepts, but it does not have the ability to perform semantic calculations, we have a lot of data mining software that has the ability to perform complex calculations but they They can only calculate variables that have physical, statistical and social properties. In addition to data mining, there is another system called text mining, unfortunately text mining software can only count the number of words in a note or the number of repetitions. Or there are a few specific words in a note, if one day meaning analysis software is created, you can use special software that of course is placed online on the web and all human beings can access it and then Use it for many problems. As guidance and analysis of separation from the spouse in certain circumstances, deciding on a standard marriage, taking action to treat a dangerous illness, buying a car and a house, the principles of dealing with a fraudster and a debtor, and thousands more. This software is able to perform these very complex calculations. It must receive a lot of information from humans and develop and upgrade its software after analyzing the information.
Of course, this software will have a very large database to which various information is injected by humans, and this intelligent software uses pure and optimal information for the general public by analyzing information by artificial intelligence, and this The software improves by itself. Of course by itself and input information from the human spectrum
Hi Magholi231, i was thinking the same thing this days, what conclusions did you get? Did you find an software to do that? what api are you using to study this subjects?
I am looking into knime, this application has a range of text analysis and other analytical tools, and I think it should be relatively easy to set it up to read in my entire vault