I followed this post on how to organize Tasks into a Dataview table, super helpful. But I’m having a hard time removing Subtasks from the first column.
Obsidian Forum | Create Dataview Table of Multiple Tasks Within Notes
I am using Dataview and Tasks community plugins
What I’m trying to do
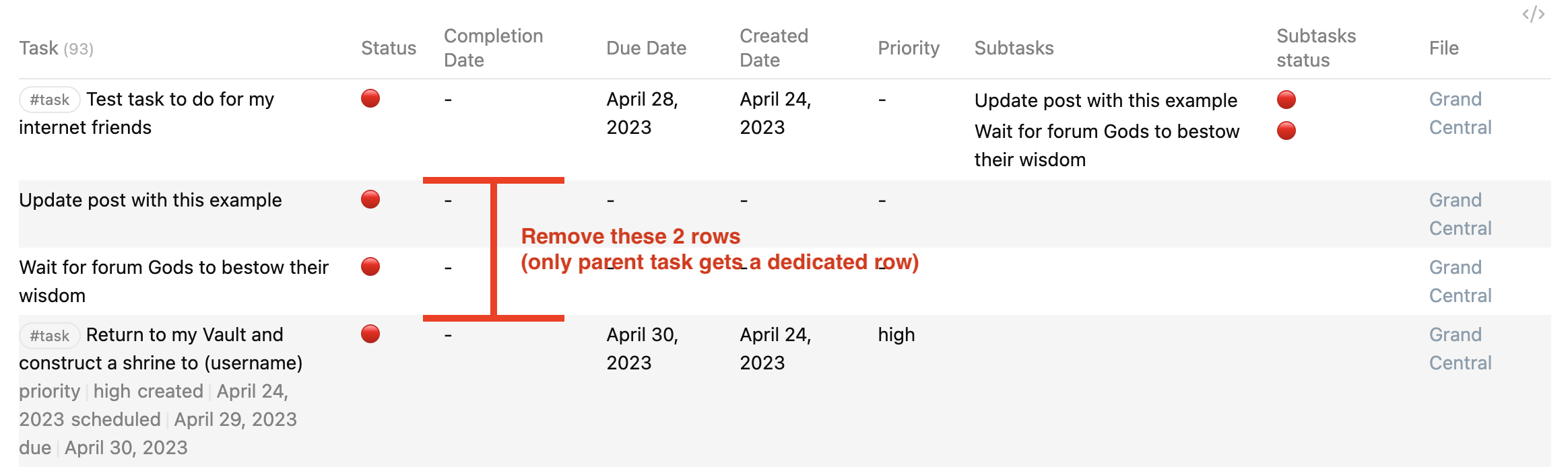
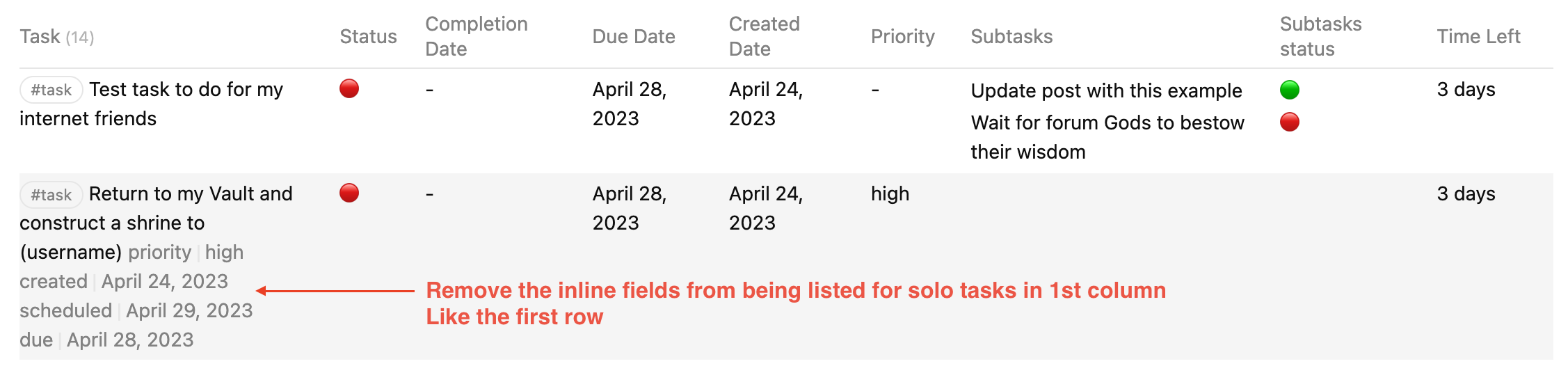
- Remove Subtasks from being listed in the first column of the Dataview table
- Filter the table to tasks from specific pages and headers
Things I have tried
- Modifying regex but I couldn’t troubleshoot it very well. I’m familiar with JavaScript but had no luck
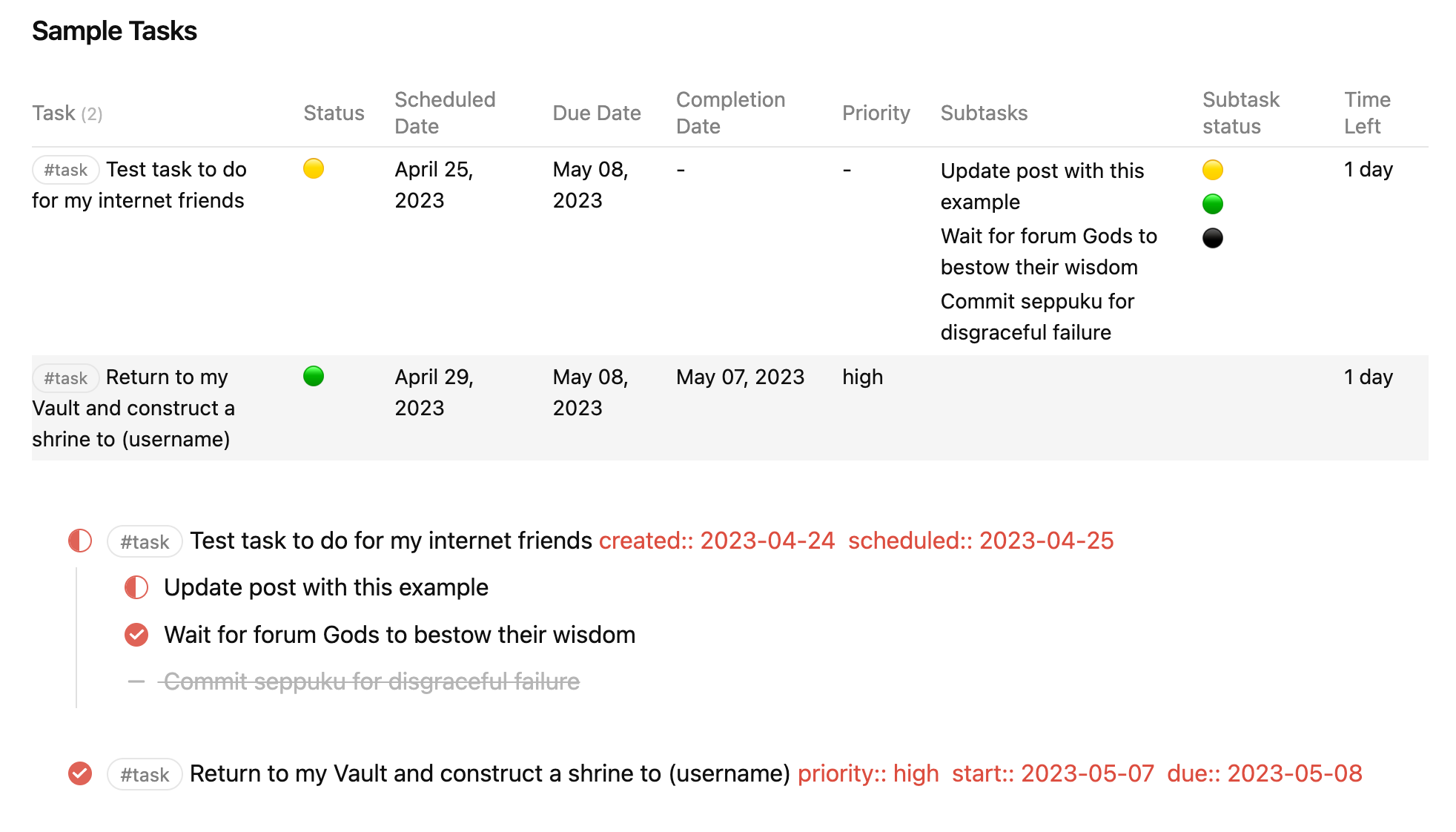
TABLE WITHOUT ID
regexreplace(Tasks.text, "\[.*$", "") AS Task,
choice(Tasks.completed, "🟢", "🔴") AS Status,
Tasks.completion AS "Completion Date",
Tasks.due AS "Due Date", Tasks.created AS "Created Date",
Tasks.priority AS "Priority",
regexreplace(Tasks.subtasks.text, "\[.*$", "") AS Subtasks,
choice(Tasks.subtasks.completed, "🟢", "🔴") AS "Subtasks status",
file.link AS "File"
FROM #task
WHERE file.tasks
FLATTEN file.tasks AS Tasks
SORT Tasks.due desc
- Including WHERE filter to grab the page and header needed according to the docs.
WHERE header = [[Page Name#Header]]
I got empty tables every time. Path, page name, extension, no extension, every variation I could think of. No luck
Thanks in advance, I really appreciate the help