I’m not sure it’ll work, but do you get your result by changing the first line to: TABLE tag, length(rows) as quantity, join(rows.file.name) as Servers
Untested, and I’m not sure if it’ll count multiple reference within one file. I do think a given tag is only be represented once for each file.
It took some time, but here we are with another query which might do what you want it to do. At least based on your previous example. Here is the requirements I based this query upon:
Limited to current file → WHERE file = this.file
Look at the list items having children with a random tag (which indirectly reads as ignore any list items having a parent → !item.parent )
Split out all those children, whilst storing the text of the parent items, aka storing the server name
Group similar tasks (aka tags) together, and give a count of them including which servers these tasks came from
The final query looks like this:
```dataview
TABLE length(rows) as Qty, join(rows.child.parentText) as Servers
FLATTEN file.lists as item
FLATTEN map(
filter( item.children, (f) => f.tags),
(m) => object("task", m, "parentText", item.text)
) as child
FLATTEN child.task.tags as ctags
WHERE file = this.file
AND !item.parent
GROUP BY ctags as Task
```
A little explanation follows:
TABLE length(rows), join(rows.child.parentText) – Later on we’ll group on the tags present in a childs task, where we also store the text of its parent. When grouped all the result are stored into the rows list
FLATTEN file.lists as item – Split out every list item into a row of its own, and combined with the !item.parent this means only look at list items not having parents, aka the server name list items
FLATTEN map( ... ) as child - This is a rather heavy one :-D, but in essence it makes a list of children having a tag, maps it into a new object, which we store as child
filter( item.children, (f) => f.tags) – This is the list used for the mapping, and its based upon the children of the current list item (aka the servers), and if either of those children have tags associated with it, we keep the child item for later mapping
(m) => object("task", m, "parentText", item.text) – This is the actual mapping where we create a new object with two fields. The task field storing all information on the child list item (e.g. “Perform #task1”), and the text of the parent items into parentText(e.g. “Server 1”)
FLATTEN child.task.tags as ctags – In case there are multiple tags on a child item, this ensure that each of those are split out into their own row in the final output
WHERE ... – Limits the overall query to only look in the current file, and to list items how doesn’t have any parents (aka top level list items (aka server names))
GROUP BY ctags as Task – Group together similar tasks, so that we’re able to count them later on. Note that all fields currently available, like child are now moved into rows.child
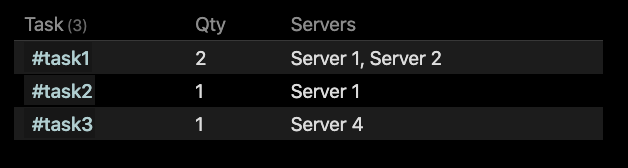
Given the example given before this result in this output:
Some more related intermediate queries
To test this I used the following note:
---
Tags: f68673
---
questionUrl:: http://forum.obsidian.md/t//68673
- Server 1
- Perform #task1
- Perform #task2
- Server 2
- Perform #task1
- Server 3
- Server 4
- Perform #task3
List the parent item (aka server) where a children item has a tag:
```dataview
TABLE WITHOUT ID
item.parent, cTask.text, cTask
FLATTEN file.lists as item
FLATTEN filter(item.children, (f) => f.tags) as cTask
WHERE file = this.file
AND !item.parent
```
Pre-grouping, storing the text of the parent:
```dataview
TABLE child.task.text, child.parentText
FLATTEN file.lists as item
FLATTEN map(
filter( item.children, (f) => f.tags),
(m) => object("task", m, "parentText", item.text)
) as child
WHERE file = this.file
AND !item.parent
```
Group children item with tags
```dataview
TABLE length(rows) as Qty, join(rows.child.parentText) as Servers
FLATTEN file.lists as item
FLATTEN map(
filter( item.children, (f) => f.tags),
(m) => object("task", m, "parentText", item.text)
) as child
FLATTEN child.task.tags as ctags
WHERE file = this.file
AND !item.parent
GROUP BY ctags as Task
```