Hello all,
I’m a relatively new Obsidian user and would really like to know if there’s a solution to this use case that doesn’t require too much customization. I think it could be helpful to others-
Use case or problem
I would like to use Obsidian as a general daily journaling tool. Something I have been doing in Notion that has been extremely helpful is creating columns for general topics in my life (Health, Work, etc.), and jot down quick notes from the day that I would like to review. After some time, I can simply concat all of the daily notes for a particular topic into one page to get a summary of that section over time.
The daily notes function is perfect for this, however I do not see a way to collect these subheadings over time.
Proposed solution
Functionality that lets me extract all text under headings into one note, while preserving the date of entry.
For example, let’s say there are many daily notes in a folder with ISO formatted dates as file names. Within these files might be sections: # Health, containing some text blocks.
I would like to run a query or command that searches all files in {path}, and extracts all text under specified {heading} into a new note, separating each extraction with the filename.
The results would look like this:
# 2022-12-01
Some text content under {heading}
# 2022-12-13
More text content in another file under {heading}
Current workaround (optional)
I can use the embedded query functionality to get this, however, there doesn’t seem to be a way to extract the query results as markdown content.
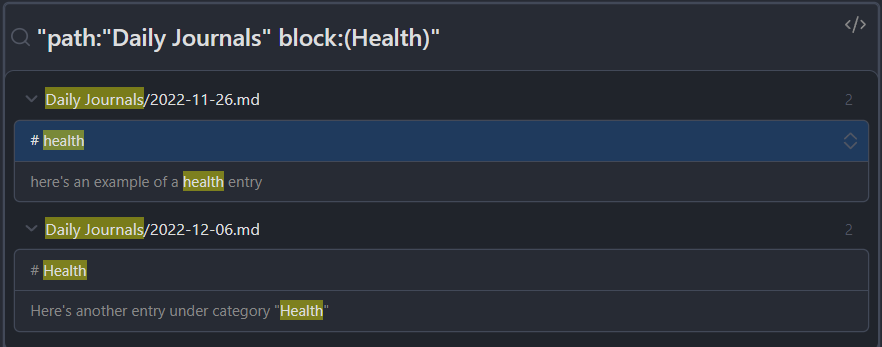
Linking to a page with {heading} is not useful, because the linked mentions pane does not allow exporting/pasting either. I’d also like not to use tags, since these are reserved for other purposes.
IMO, this functionality would be a powerful tool to turn unstructured notes into focused bullet journals. Thoughts?
PS - I found two related plugins, but I don’t think any of them match the exact functionality I described

