I’ve checked out solutions available here, but the ones I’ve tried require too much friction:
- click on the button,
- copy the text,
- create a new file manually,
- paste the text.
Some of them do download the actual file, but they place it in ~/Downloads and you have to manually move them over.
My solution:
- click on the button in your browser.
That’s it! It automatically creates the file, adds some metadata at the top of the Markdown file, and you can see it straight from your Obsidian.
Example
- I went to the random article on my Medium homepage: https://medium.com/@lancengym/the-endgame-for-linkedin-is-coming-31d4a8b2a76
- I clicked on the button, which created a file named
20200701-the_endgame_for_linkedin_is_coming.mdwhose top looks like this:
# The Endgame for LinkedIn Is Coming
* **Source:** [medium.com](https://medium.com/@lancengym/the-endgame-for-linkedin-is-coming-31d4a8b2a76)
* **Author:** Lance Ng
* **Word count:** 1844
* **Extracted at:** 2020-07-01 14:03

After two years, Microsoft still hasn’t delivered on its grand vision for LinkedIn. And it may never do so. [...]
It saves the full content, adds some metadata, and loads images externally from the same location as the article.
How to set it up
-
Make sure you have python3 installed, though it should be available out of the box in most Linux distributions.
-
Install mercury-parser somewhere in your path:
npm -g install @postlight/mercury-parser(yarnalso works). -
Modify the 9th line in the script below to point to the directory where you will store the links. Use absolute path instead of relative (so
/home/input_sh/Notesinstead of~/Notes). -
Install External Application Button in your preferred browser.
-
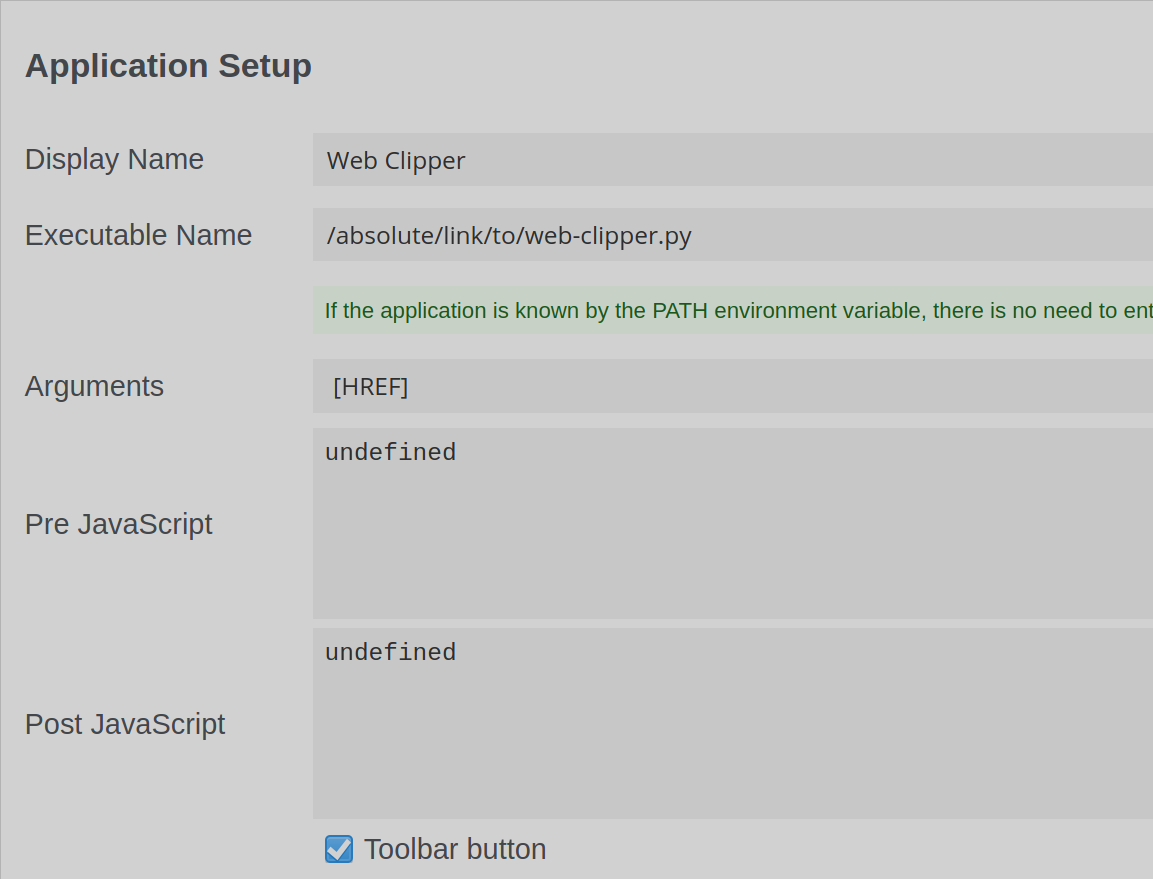
Fill out its preferences like this:
-
There’s also a “Surround arguments with quote characters” option below what’s visible in the screenshot, which would be nice to tick. Optionally, you can also upload a custom icon to be shown in your browser’s interface (32x32), as well as to close the tab automatically when the button in clicked.
Script
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import os, sys, json
import datetime
link = str(sys.argv[1])
print("Processing " + link)
directory = "/home/input_sh/Notes/Links/"
resp = json.loads(os.popen("mercury-parser " + link + " --format=markdown").read())
today = datetime.datetime.now()
out_content = resp["content"]
out_title = resp["title"]
out_url = resp["url"]
out_domain = resp["domain"]
out_wc = resp["word_count"]
if resp["author"]:
out_author = resp["author"]
else:
out_author = "Unknown"
# Ewww, www
if "www." in out_domain:
out_domain = out_domain.replace("www.", "")
if resp["lead_image_url"]:
out_lead_img = resp["lead_image_url"]
header = "* **Source:** [" + out_domain + "](" + out_url + ")\n* **Author:** " + out_author + "\n* **Word count:** " + str(out_wc) + "\n* **Extracted at:** " + today.strftime("%Y-%m-%d %H:%M") + "\n\n"
content = "# " + out_title + "\n\n" + header + "\n\n" + out_content
else:
header = "* **Source:** [" + out_domain + "](" + out_url + ")\n* **Author:** " + out_author + "\n* **Word count:** " + str(out_wc) + "\n* **Extracted at:** " + today.strftime("%Y-%m-%d %H:%M") + "\n\n---\n\n"
content = "# " + out_title + "\n\n" + header + out_content
# Formats the title of the file
title = today.strftime("%Y%m%d-" + out_title)
title = title.lower().replace(" ", "_").replace("(", "").replace(")", "")
# Writes to the actual file
f = open(os.path.join(directory + title + ".md"), "w+", encoding="utf-8")
f.write(content)
f.close()
print("Done!")
Don’t forget to make the script executable! If you’ve saved the script as web-clipper.py, you’d do something like chmod +x web-clipper.py. You can test if it works from your terminal by running ./web-clipper.py "https://medium.com/@lancengym/the-endgame-for-linkedin-is-coming-31d4a8b2a76" before you proceed with setting up External Application Button.
Feel free to let me know if you encounter some quirks.


