I wanted to post an updated version of my templates. I was inspired by the upper and lower cases aliases post as well as just some more playing around.
The updated templates will:
- automatically query for more varied relevant information and will accommodate for different aliases (but only upper and lower cases aliases based on the titles)
- automatically query for files that are related to the number IDs (so if you were using the Luhmann appending ID, this would automatically detect.
- for example, if you have a file that is called “420.69 dank memes” and you also have a file that is called “420.69a where is the nearest 24-7 convenience store”, both files should detect each other.
L1 are proto-MOCs

L2 are sub-notes
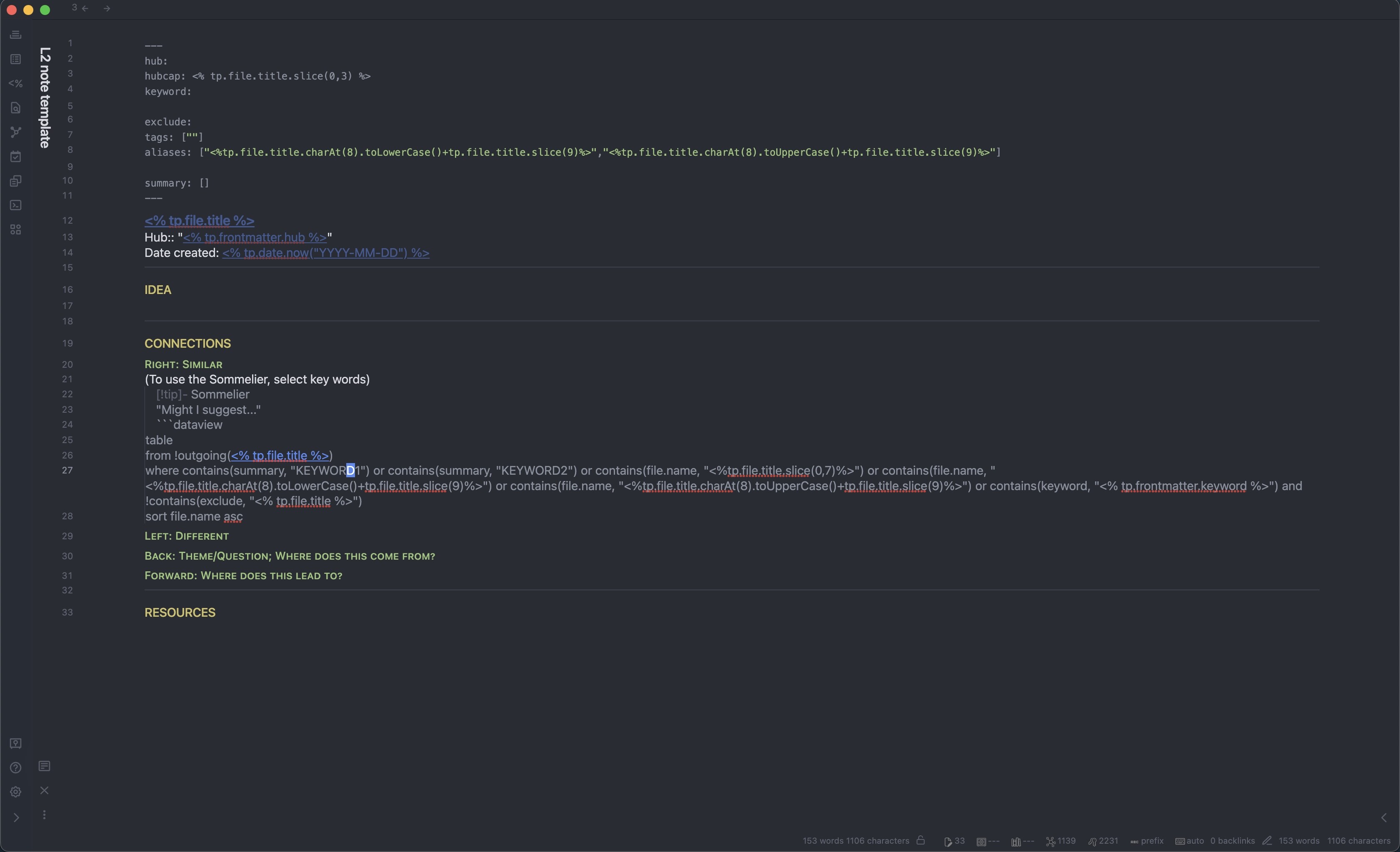
For L2 summary KEYWORD1 and KEYWORD2, you need to manually input them into the query.
Also, be aware that the .slice() function will need to be adjusted to your individual use case. The numbers I used only apply to the specific number ID configuration that I personally use.