Steps to reproduce
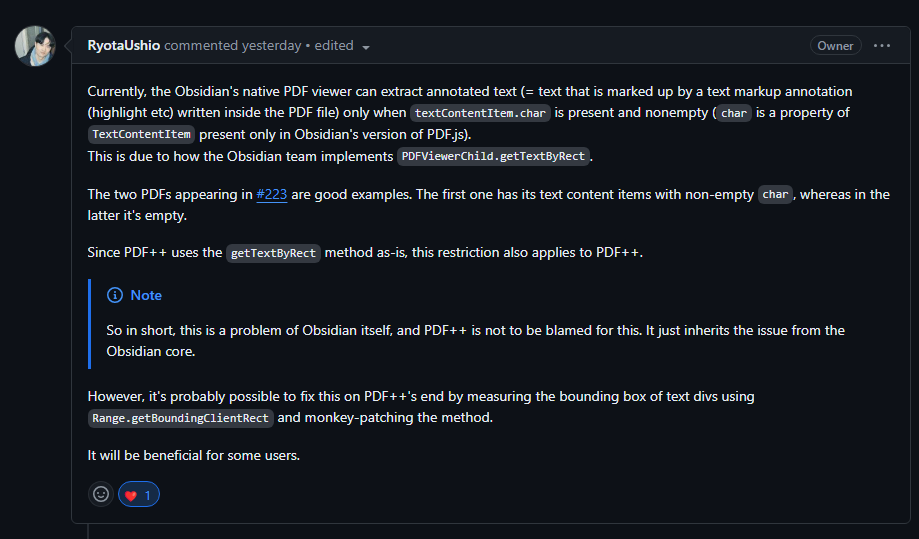
Following all steps assessed as well as the official request from the primary maintainer of PDF++, this bug report is intended to show that not all PDFs in the upstream annotator match the call comment that Obsidian uses in its default annotator. As a result all plugins for PDF functionality inherent an issue were some OCRs for PDFs fail to be captured by the extractor
(Note: take the above description with a grain of salt. I was asked by the developer to submit this and wrote this as well as I could given I’m not a developer))
Did you follow the troubleshooting guide?
Yes.
Did you try the above steps in the sandbox vault?
This was tried and proven to have occurred using the default sandbox as shown here:
Link: Not sure what is different, or if it's Adobe, but something weird is happening... · RyotaUshio/obsidian-pdf-plus · Discussion #223 · GitHub
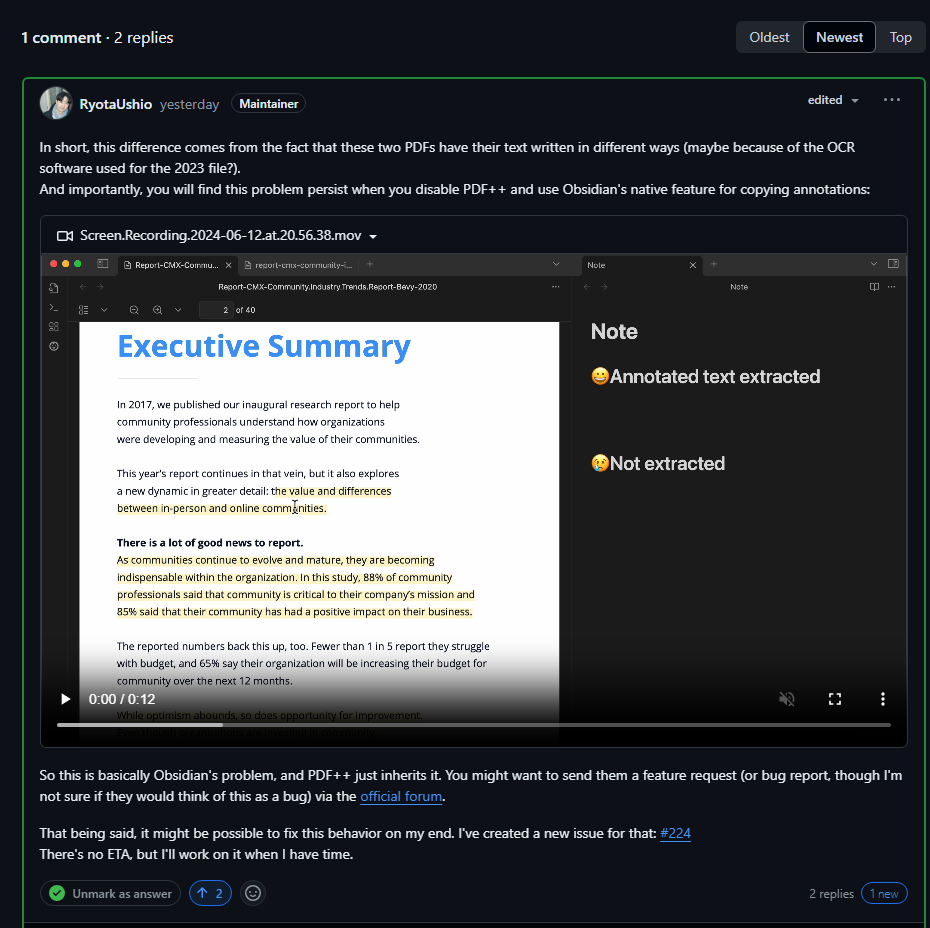
Expected result
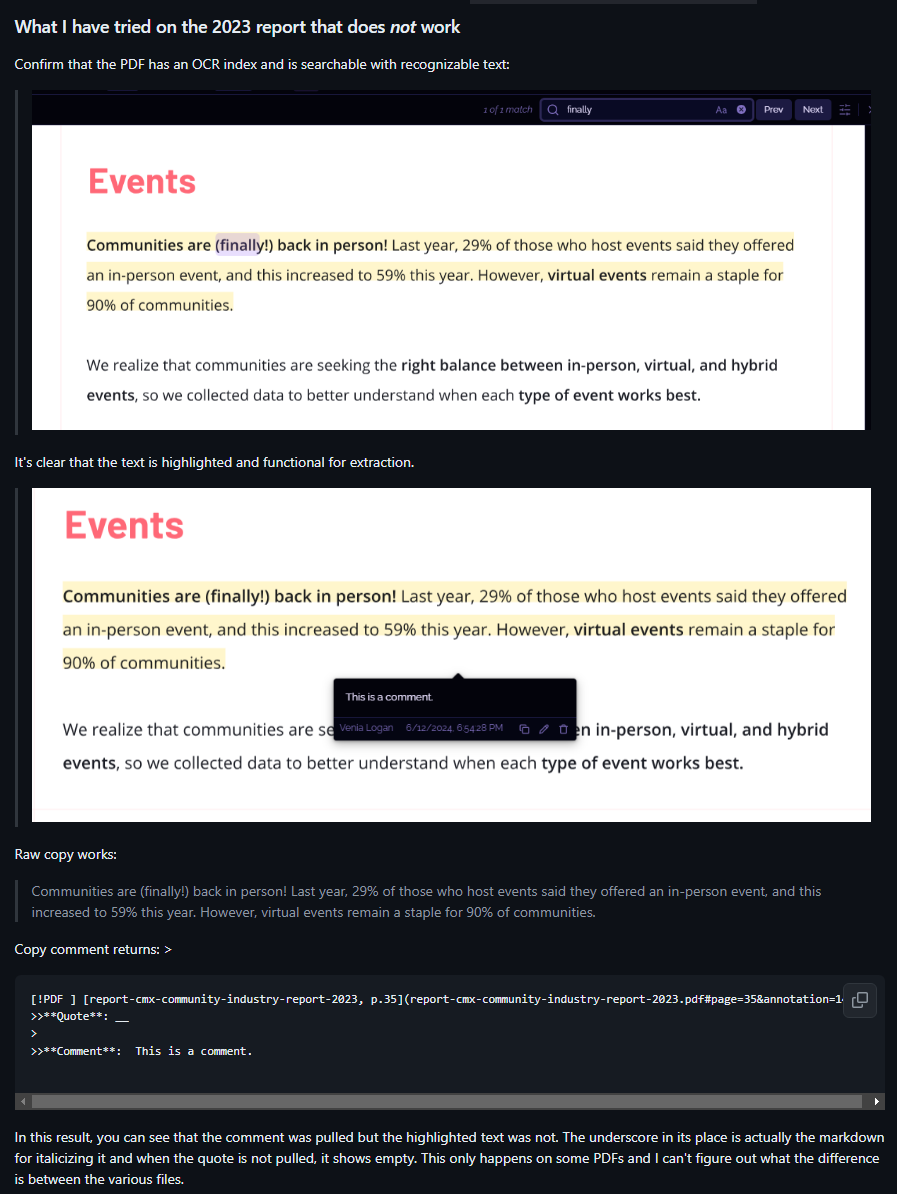
As stated the issue only occurs on some PDFs and as I’m submitting this ticket I’m still honestly not sure how this works. It may be worth reaching out to @ush directly. That said, My personal contribution which brought this to his attention is linked here, and the expected result is as follows in the image:
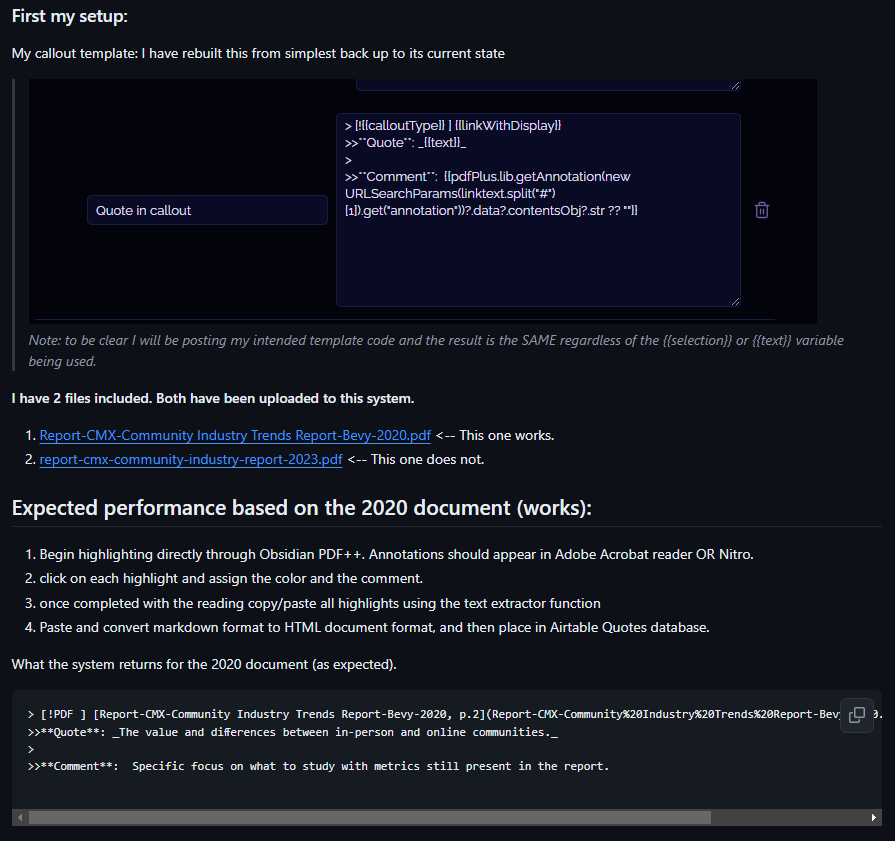
Actual result
As listed further down in my response you can see that the 2023 PDF (the one that does not work, returned and extracted a null highlight. I cannot figure out what defines a PDF that works vs. one that doesn’t for either the comment pulled, nor the highlight itself.
Environment
SYSTEM INFO:
Obsidian version: v1.6.3
Installer version: v1.5.12
Operating system: Windows 10 Pro 10.0.22631
Login status: logged in
Catalyst license: none
Insider build toggle: off
Live preview: on
Base theme: dark
Community theme: Vauxhall v1.0.1
Snippets enabled: 1
Restricted mode: off
Plugins installed: 12
Plugins enabled: 8
1: Auto Link Title v1.5.4
2: TagFolder v0.18.7
3: ePub Reader v1.0.2
4: Tag Wrangler v0.6.1
5: Media Extended v3.1.0
6: PDF++ v0.39.23
7: Dataview v0.5.66
8: Text Extractor v0.5.2
Additional information
For additional information (because I am definitely not the one to talk to about this), please contact @ush.