Jump Ship is a fully-fledged end-to-end service that enables you to simply and easily import very large and complex Notion workspaces for use in Obsidian.
The default ZIP export process Notion uses can result in errors, unreliable export of pages and poor formatting of content. For large workspaces especially, the Importer plug-in just doesn’t work.
We mitigate that by going directly through the Notion API, allowing for a pristine export of your workspace, grabbing as much data as possible.
Get started by registering for open beta access!
Here’s a few screenshots of the service in action.
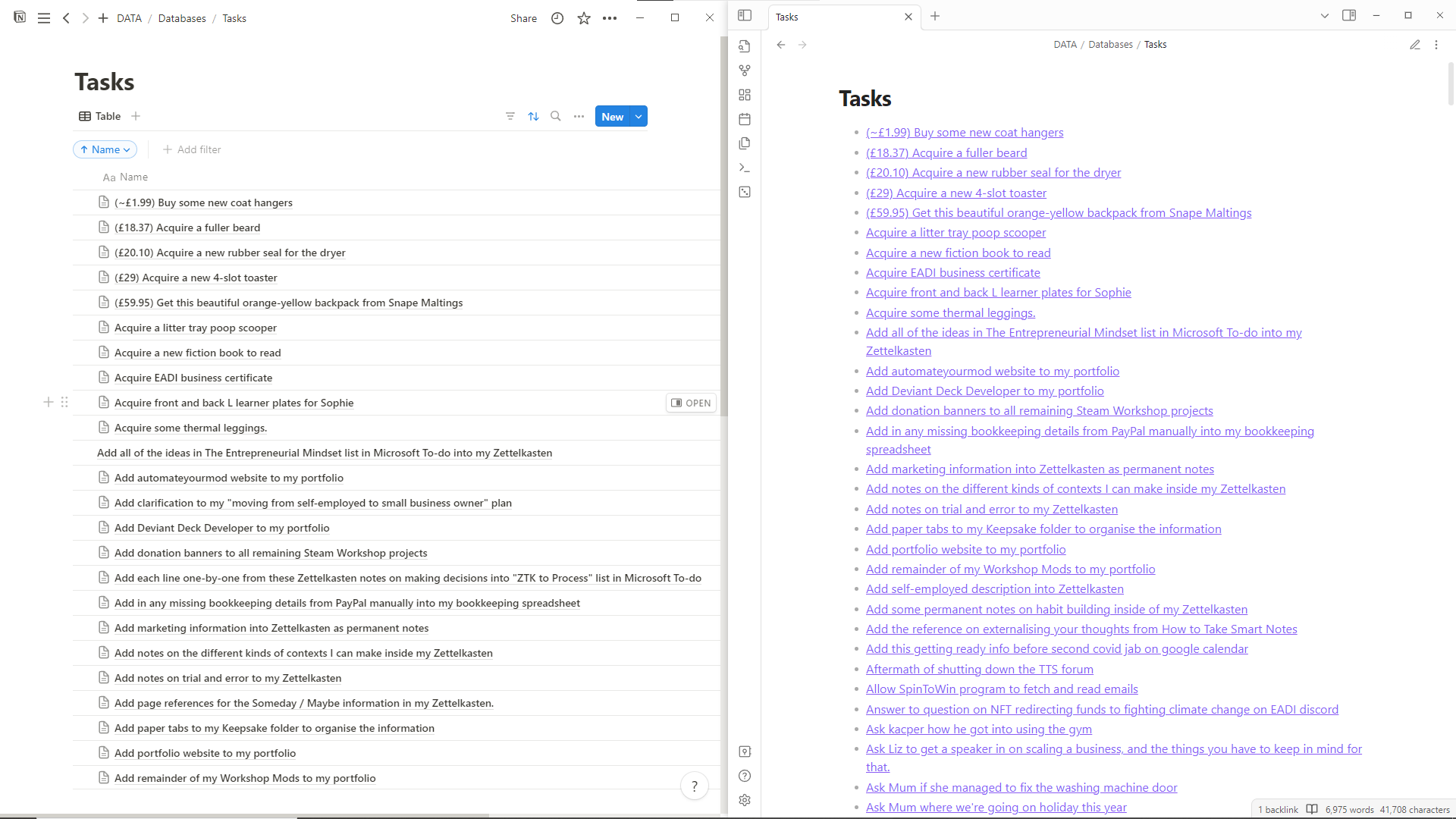
Database preview side-by-side, Notion left, Obsidian right.
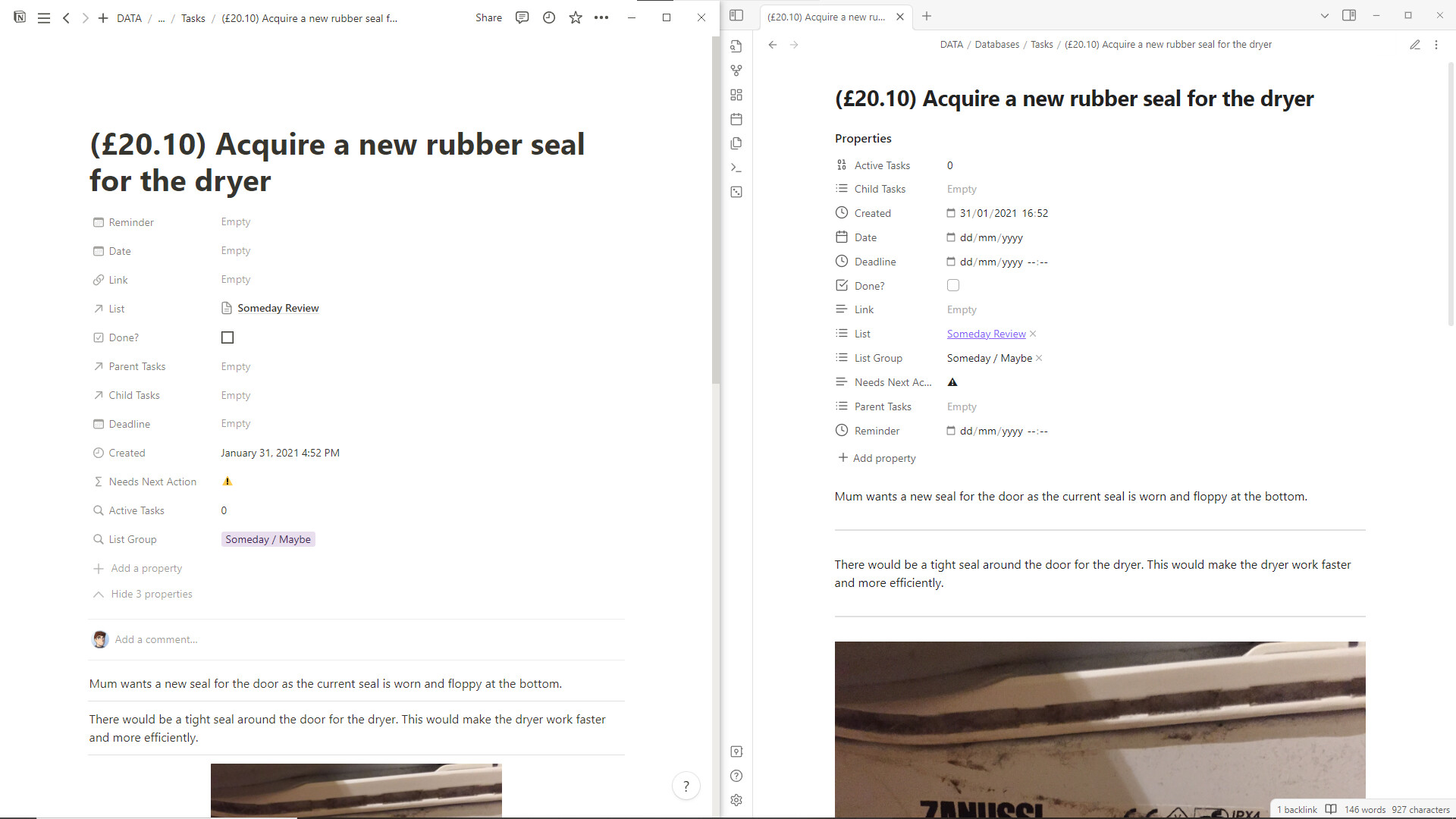
Properties & images carrying over from Notion to Obsidian.
What does open beta access mean?
We are still developing the website, the back-end, and everything involved in getting people’s data across. The service works, is functional, and works end-to-end for most people’s workspaces, though there may be errors in very niche situations.
The best way to test out whether our service is for you is through generating a free sample workspace using your own notes.
- Try out the service;
- Let us know at our support e-mail ([email protected]) if you need any help with the formatting of your export.
- We will work with you to get that right.
What does Jump Ship support?
Jump Ship is designed to comprehensively transfer as much data as possible.
This includes:
- Tables.
- Links.
- Relations.
- Databases.
- Images.
- Files.
- And more…
We are considering adding comment support in the future if there is a considerable amount of demand for it. Please reach out to our support e-mail if this is something you’re looking for: [email protected]
Is it safe?
We care about user privacy, you can read our privacy policy here. In summary though: no we don’t read your workspaces, no we won’t sell your data, and data is periodically deleted after a certain period of time.
We aim to be more transparent about how we manage user data in the future, though in the mean-time if you have any questions or feedback regarding this, please reach out to our support e-mail: [email protected]
Any other questions?
Our Jump Ship documentation should cover most questions, so please have a look through here for answers first. If it’s not there, reply here or reach out to our support e-mail and we will try and address it: [email protected]
Get started by registering for open beta access!