I’ve cloned the repo, and added my previous suggestion into the WHERE clause, and it seems to work just fine. I didn’t like the look of duplicate entries, so I changed that (hopefully without breaking other logic), and moved the entire query into a file of its own.
File: zzMeta/dv/GalleryDQL
I placed the query in the filename given above, so that it would appear at the bottom of your vault. This can of course be changed to whatever you feel like, and it’s content are as follows:
TABLE without id
("") AS "Cover",
P_BookByAuthor + P_MediumIcon + P_FavoriteIcon AS "Title",
Q_YearRating + Q_PagesHours + " || " + Q_FLAG AS "Time and Place",
R_Dates AS "Dates",
"(" + S_ReadingTime + " || " + S_ReadingSpeed + ")" AS "Reading Time"
FROM "Book Log" OR "Y Movies and Games" OR "0 Currently Reading" OR "Set Aside"
WHERE filter(choice(typeof(country) = "array", country, list(country)),
(c) => meta(c).path = this.file.path)
FLATTEN array( {
"Book": Author,
"Audiobook": Author,
"Podcast": Author,
"eBook": Author,
"AcademicBook": Author,
"AcademicArticle": Author,
"GraphicNovel": Author,
"Movie": Director,
"TV": Director,
"Game": Director
}[Medium] ) AS Creator
FLATTEN link(file.link, Alias) + " by " + Creator AS P_BookByAuthor
FLATTEN choice(contains(tags, "Favorite"), "💛", "") AS P_FavoriteIcon
SORT DateFinished desc
FLATTEN {
"Book": " 📖 ",
"Audiobook": " 🎧 ",
"Podcast": " 📻 ",
"eBook": " 📃 ",
"AcademicBook": " 📚🎓 ",
"AcademicArticle": " 📰 ",
"GraphicNovel": " 💬 ",
"Movie": " 🎞️ ",
"TV": " 📺 ",
"Game": " 🎮 "
}[Medium] AS P_MediumIcon
FLATTEN DateStarted + " — " + DateFinished AS R_Dates
FLATTEN choice(((DateFinished - DateStarted).days = 1), "1 day", choice((DateFinished != DateStarted), (DateFinished - DateStarted).days + " days", "0 days" )) AS S_ReadingTime
FLATTEN {
"Book": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 1) + " p/d",
"Audiobook": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 2) + " h/d",
"Podcast": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 2)+ " h/d",
"eBook": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 1) + " p/d",
"GraphicNovel": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 1) + " p/d",
"AcademicBook": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 1) + " p/d",
"AcademicArticle": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 1) + " p/d",
"Movie": round(choice((DateFinished = DateStarted), round((Length/60), 1), (Length / (DateFinished - DateStarted).days)), 1) + " h/d",
"TV": round(choice((DateFinished = DateStarted), round((Length/60), 1), (Length / (DateFinished - DateStarted).days)), 1) + " h/d",
"Game": round(choice((DateFinished = DateStarted), round((Length/60), 1), (Length / (DateFinished - DateStarted).days)), 1) + " h/d"
}[Medium] AS S_ReadingSpeed
FLATTEN Year + " || " + " ⭐ " + Rating + " || " AS Q_YearRating
FLATTEN {
"Book": Length + " p",
"Audiobook": Length + " h",
"Podcast": Length + " h",
"eBook": Length + " p",
"GraphicNovel": Length + " p",
"AcademicBook": Length + " p",
"AcademicArticle": Length + " p",
"Movie": round((Length/60), 1) + " h",
"TV": round((Length/60), 1) + " h",
"Game": round((Length/60), 1) + " h"
}[Medium] AS Q_PagesHours
FLATTEN join(map(choice(typeof(Country) = "array", Country, list(Country)), (c) => link(
meta(c).path, {
AD: "🇦🇩", AE: "🇦🇪", AF: "🇦🇫", AG: "🇦🇬", AI: "🇦🇮", AL: "🇦🇱", AM: "🇦🇲", AO: "🇦🇴", AQ: "🇦🇶", AR: "🇦🇷", AS: "🇦🇸", AT: "🇦🇹", AU: "🇦🇺", AW: "🇦🇼", AX: "🇦🇽", AZ: "🇦🇿",
BA: "🇧🇦", BB: "🇧🇧", BD: "🇧🇩", BE: "🇧🇪", BF: "🇧🇫", BG: "🇧🇬", BH: "🇧🇭", BI: "🇧🇮", BJ: "🇧🇯", BL: "🇧🇱", BM: "🇧🇲", BN: "🇧🇳", BO: "🇧🇴", BQ: "🇧🇶", BR: "🇧🇷", BS: "🇧🇸", BT: "🇧🇹", BV: "🇧🇻", BW: "🇧🇼", BY: "🇧🇾", BZ: "🇧🇿",
CA: "🇨🇦", CC: "🇨🇨", CD: "🇨🇩", CF: "🇨🇫", CG: "🇨🇬", CH: "🇨🇭", CI: "🇨🇮", CK: "🇨🇰", CL: "🇨🇱", CM: "🇨🇲", CN: "🇨🇳", CO: "🇨🇴", CR: "🇨🇷", CU: "🇨🇺", CV: "🇨🇻", CW: "🇨🇼", CX: "🇨🇽", CY: "🇨🇾", CYMRU: "🏴", CZ: "🇨🇿",
DE: "🇩🇪", DJ: "🇩🇯", DK: "🇩🇰", DM: "🇩🇲", DO: "🇩🇴", DZ: "🇩🇿",
EC: "🇪🇨", EE: "🇪🇪", EG: "🇪🇬", EH: "🇪🇭", ENG: "🏴", ER: "🇪🇷", ES: "🇪🇸", ET: "🇪🇹",
FI: "🇫🇮", FJ: "🇫🇯", FK: "🇫🇰", FM: "🇫🇲", FO: "🇫🇴", FR: "🇫🇷",
GA: "🇬🇦", GB: "🇬🇧", GD: "🇬🇩", GE: "🇬🇪", GF: "🇬🇫", GG: "🇬🇬", GH: "🇬🇭", GI: "🇬🇮", GL: "🇬🇱", GM: "🇬🇲", GN: "🇬🇳", GP: "🇬🇵", GQ: "🇬🇶", GR: "🇬🇷", GS: "🇬🇸", GT: "🇬🇹", GU: "🇬🇺",GW: "🇬🇼", GY: "🇬🇾",
HK: "🇭🇰", HM: "🇭🇲", HN: "🇭🇳", HR: "🇭🇷", HT: "🇭🇹", HU: "🇭🇺",
ID: "🇮🇩", IE: "🇮🇪", IL: "🇮🇱", IM: "🇮🇲", IN: "🇮🇳", IO: "🇮🇴", IQ: "🇮🇶", IR: "🇮🇷", IS: "🇮🇸", IT: "🇮🇹",
JE: "🇯🇪", JM: "🇯🇲", JO: "🇯🇴", JP: "🇯🇵",
KE: "🇰🇪", KG: "🇰🇬", KH: "🇰🇭", KI: "🇰🇮", KM: "🇰🇲", KN: "🇰🇳", KP: "🇰🇵", KR: "🇰🇷", KW: "🇰🇼", KY: "🇰🇾", KZ: "🇰🇿",
LA: "🇱🇦", LB: "🇱🇧", LC: "🇱🇨", LI: "🇱🇮", LK: "🇱🇰", LR: "🇱🇷", LS: "🇱🇸", LT: "🇱🇹", LU: "🇱🇺", LV: "🇱🇻", LY: "🇱🇾",
MA: "🇲🇦", MC: "🇲🇨", MD: "🇲🇩", ME: "🇲🇪", MF: "🇲🇫", MG: "🇲🇬", MH: "🇲🇭", MK: "🇲🇰", ML: "🇲🇱", MM: "🇲🇲", MN: "🇲🇳", MO: "🇲🇴", MP: "🇲🇵", MQ: "🇲🇶", MR: "🇲🇷", MS: "🇲🇸", MT: "🇲🇹", MU: "🇲🇺", MV: "🇲🇻", MW: "🇲🇼", MX: "🇲🇽", MY: "🇲🇾", MZ: "🇲🇿",
NA: "🇳🇦", NC: "🇳🇨", NE: "🇳🇪", NF: "🇳🇫", NG: "🇳🇬", NI: "🇳🇮", NL: "🇳🇱", NO: "🇳🇴", NP: "🇳🇵", NR: "🇳🇷", NU: "🇳🇺", NZ: "🇳🇿",
OM: "🇴🇲",
PA: "🇵🇦", PE: "🇵🇪", PF: "🇵🇫", PG: "🇵🇬", PH: "🇵🇭", PK: "🇵🇰", PL: "🇵🇱", PM: "🇵🇲", PN: "🇵🇳", PR: "🇵🇷", PS: "🇵🇸", PT: "🇵🇹", PW: "🇵🇼", PY: "🇵🇾",
QA: "🇶🇦",
RE: "🇷🇪", RO: "🇷🇴", RS: "🇷🇸", RU: "🇷🇺", RW: "🇷🇼",
SA: "🇸🇦", SB: "🇸🇧", SC: "🇸🇨", SCOT: "🏴", SD: "🇸🇩", SE: "🇸🇪", SG: "🇸🇬", SH: "🇸🇭", SI: "🇸🇮", SJ: "🇸🇯", SK: "🇸🇰", SL: "🇸🇱", SM: "🇸🇲", SN: "🇸🇳", SO: "🇸🇴", SR: "🇸🇷", SS: "🇸🇸", ST: "🇸🇹", SV: "🇸🇻", SX: "🇸🇽", SY: "🇸🇾", SZ: "🇸🇿",
TC: "🇹🇨", TD: "🇹🇩", TF: "🇹🇫", TG: "🇹🇬", TH: "🇹🇭", TJ: "🇹🇯", TK: "🇹🇰", TL: "🇹🇱", TM: "🇹🇲", TN:"🇹🇳", TO: "🇹🇴", TR: "🇹🇷", TT: "🇹🇹", TV: "🇹🇻", TW: "🇹🇼", TZ: "🇹🇿",
UA: "🇺🇦", UG: "🇺🇬", UM: "🇺🇲", US: "🇺🇸", UY: "🇺🇾", UZ: "🇺🇿",
VA: "🇻🇦", VC: "🇻🇨", VE: "🇻🇪", VG: "🇻🇬", VI: "🇻🇮", VN: "🇻🇳", VU: "🇻🇺",
WF: "🇼🇫", WS: "🇼🇸",
YE: "🇾🇪", YT: "🇾🇹",
ZA: "🇿🇦", ZM: "🇿🇲", ZW: "🇿🇼"
}[meta(c).display]
)), ", ") AS Q_FLAG
And with the following in the China file:
```dataviewjs
dv.execute(await dv.io.load("zzMeta/dv/GalleryDQL.md"))
```
I got this output:
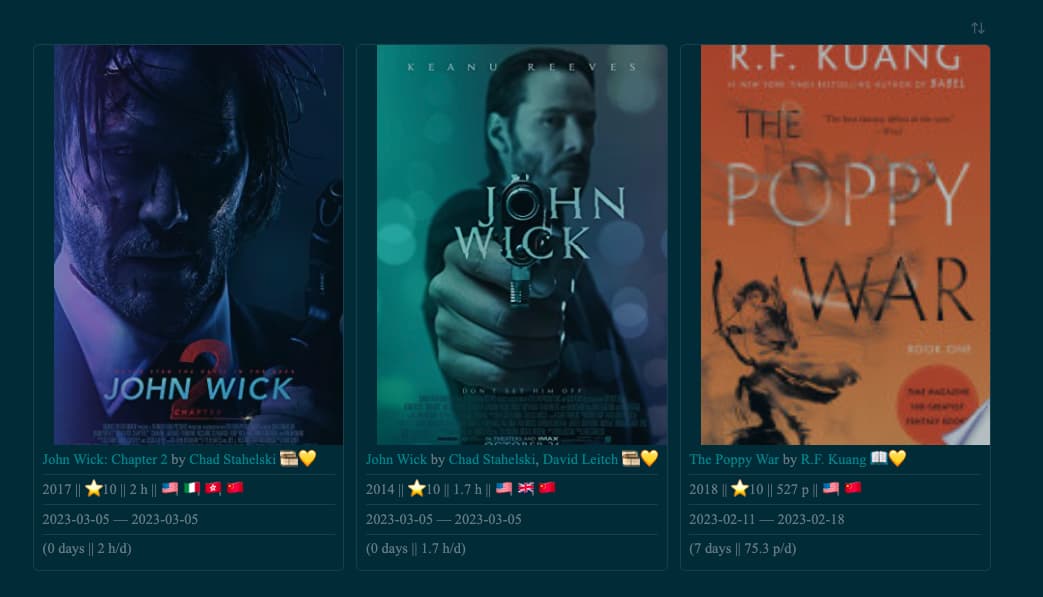
Notice how it lists both of the creators of “John Wick”, and lists multiple countries for all the books.
For United Kingdom, it includes both the “John Wick” and the “The Audiobook of the Year 2018”.
Splitting up the DQL query
I’ve focused here on just this one DQL query, but it could be considered useful to split that query into multiple parts. For example one could argue the case that the definition of the Q_FLAG should be considered a separate query, as one can easily see it reused in other queries.
One sample setup for this would then to remove that part out of GalleryDQL.md into another file Q_FLAG.md, and use something like the following to build the “new” full query:
```dataviewjs
const mainQuery = await dv.io.load("zzMeta/dv/GalleryDQL.md")
const Q_FLAG = await dv.io.load("zzMeta/dv/Q_FLAG.md")
dv.execute(mainQuery + Q_FLAG)
```
This syntax allows for using different parts as building bricks of your query, but it doesn’t allow for anything to be changed within one of the parts. It could still be useful when dealing with vaults like yours since the metadata structure is somewhat fixed.
Two other variations does although exist, having the “main query” as text inline and then bits and pieces in query part notes, and to use dv.view() and allow for the parts to be modified like with different column names, and stuff like that. I’m not going to cover that last part here, but I’m going to show a variant of the first suggestion here:
```dataviewjs
const mainQuery = `
TABLE without id
("") AS "Cover",
P_BookByAuthor + P_MediumIcon + P_FavoriteIcon AS "Title",
Q_YearRating + Q_PagesHours + " || " + Q_FLAG AS "Time and Place",
R_Dates AS "Dates",
"(" + S_ReadingTime + " || " + S_ReadingSpeed + ")" AS "Reading Time"
FROM "Book Log" OR "Y Movies and Games" OR "0 Currently Reading" OR "Set Aside"
WHERE filter(choice(typeof(country) = "array", country, list(country)),
(c) => meta(c).path = this.file.path)
`
const AuthorStuff = await dv.io.load("zzMeta/dv/AuthorStuff.md")
const FavoriteStuff = await dv.io.load("zzMeta/dv/FavoriteStuff.md")
const ReadingStuff = await dv.io.load("zzMeta/dv/ReadingStuff.md")
const Q_FLAG = await dv.io.load("zzMeta/dv/Q_FLAG.md")
dv.execute(mainQuery + AuthorStuff + FavoriteStuff + ReadingStuff + Q_FLAG)
```
That last part could be written in various different ways, here is one which includes a “random” sorting line in the midst of the various parts:
dv.execute([
mainQuery,
AuthorStuff,
"SORT DateFinished desc",
FavoriteStuff,
ReadingStuff,
Q_FLAG,
].join("\n"))
What goes in which part and so on, depends on which part of your queries varies, and what makes sense for you to include in various queries.
The advantage of this latter variant, is that it allowsfor the main part of the query to be seen without needing to look into other files, whilst still keeping the bulk of the query in imported files.
The overall advantage of having either part or the entire query in separate files, is that then you need only to update one (or a few) query parts when something changes. And you don’t need to go into all of the country files (for example) to update your queries.