Cool glad it is working out for you! 
re: standardization, I saw a good quote yesterday (no known source, randomly found in a comment online) that resonates deeply with me and matches exactly what you are seeing:
Complex systems breed simple behavior; simple systems breed complex behavior.
I spent a LOT (seriously, a LOT) of time grappling with systems and workflows, enough perhaps to practically write a book on this stuff lol (for example, my single outline note on note taking principles is 6 printed pages containing almost 70 links to evergreen and lit notes on various principles I’ve extracted, and I have a similar separate note comparing various note taking systems, and several deep diving into Luhmann’s process… I went nuts lol) and eventually iterated to this solution which (so far) works well, providing enough structure to add value and meaning without being so complex that it unnecessarily constricts my actions. It rewards tweaks and adaptations and “rule breaking” rather than forcing me to fight against myself.
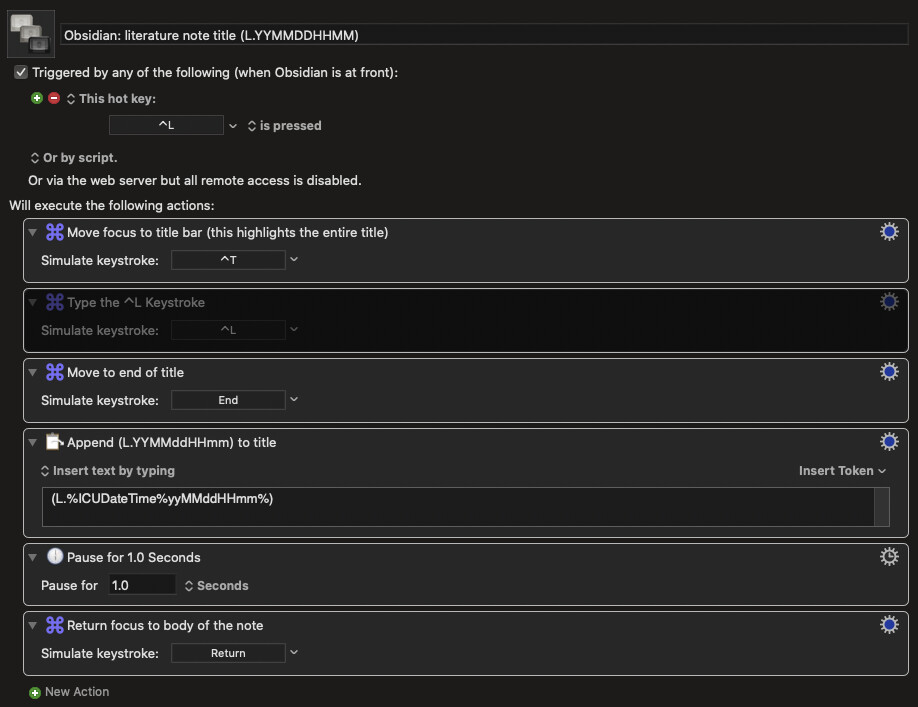
Yes the IDs really are there just to ensure no collisions when I create a file from somewhere outside Obsidian. Obsidian would detect a collision if I created a duplicate inside Obsidian, but when creating from outside e.g. Alfred it is a risk, so the IDs remove that risk. I don’t really attach any significance to the date, but it does have a secondary benefit of providing a search vector if needed.
For example, if I’m looking for a note on the deep-rooted philosophical meanings of the complex lyrics of Silento’s classical masterpiece, and I know I wrote the note in the year 2082, I could simply use fuzzy search for something like philnae(.82 and it would find it fast. But that’s not a primary goal at all.
For reference, here’s my Keyboard Maestro macro for adding the lit note ID: