The original post is a dense presentation of the problem. I will try to unpack it:
Part 1
“Imagine there is a vault V which contains a bunch of pages P each with a unique set of tags u for a dateview field, attribute A.”
This means… I want you to imagine there is a stack of markdown files which we can agree comprises an Obsidian vault. Let’s refer to that vault here by the following symbol: V
Let’s agree that each file in V is called a ‘page’.
Please imagine that there is subset of pages (let’s call this sub-collection P) in V that has the following property:
Each page in P has a dataview field called attribute_A, and the value of this field is a unique bunch of tags. (Let’s refer to any one of these unique bunches as u. So, if we want to talk about one of these bunch but it doesn’t matter which one, we call it u.)
To partly concretise what’s been discussed so far we can model five random pages from P as follows:
Random Page 1 in P
attribute_A:: #apple, #cat, #leaf
Blah, blah, blah content; this can be anything.
Random Page 2 in P
attribute_A:: #road, #water, #sky
Blah, blah, blah content; this can be anything.
Random Page 3 in P
attribute_A:: #person, #food, #dog
Blah, blah, blah content; this can be anything.
Random Page 4 in P
attribute_A:: #wheel, #bird, #pencil
Blah, blah, blah content; this can be anything.
Random Page 5 in P
attribute_A:: #shop, #gate, #surfboard
Blah, blah, blah content; this can be anything.
Since we agreed to refer to any of the individual collections of tags with u it follows that #person, #food, #dog can be referred to with u, and so can #road, #water, #sky. The symbol u just refers to any one of tag collections associated with an attribute_A on some page in P, (it doesn’t matter which tag collection).
Recap: I have just shown a random pick of five pages in P, which is the subset of pages in V which have the dataview field attribute_A.
Part 2
“Also, imagine that spread throughout vault V on random pages R are a collection of tasks T each of which have a bunch of tags t associated with them.”
Pages
This means… Some of the pages in V have tasks on them, and we can label this subset of V as R.
Let’s update three of five modeled pages featured above and unveil a couple of pages not in P (but which are in V) to reflect this new information:
Random Page 1 in P
attribute_A:: #apple, #cat, #leaf
Blah, blah, blah content; this can be anything.
- [ ] task r #frog, #water, #egg
- [ ] task h #road, #water, #sky
- [ ] task a #shop, #gate, #surfboard
- [ ] task q #road, #cat, #sky
Random Page 2 in P
attribute_A:: #road, #water, #sky
Blah, blah, blah content; this can be anything.
- [ ] task w #shop, #gate, #surfboard
- [ ] task b #road, #water, #sky
- [ ] task c #apple, #cat, #leaf
- [ ] task y #shop, #gate, #surfboard
Random Page 5 in P
attribute_A:: #shop, #gate, #surfboard
Blah, blah, blah content; this can be anything.
- [ ] task o #shop, #gate, #surfboard
- [ ] task m #apple, #cat, #leaf
Random Page 6 NOT in P but still a member of V
Blah, blah, blah content; this can be anything.
- [ ] task t #wheel, #bird, #pencil
- [ ] task s #road, #water, #sky
- [ ] task l #apple, #cat, #leaf
- [ ] task z #person, #food, #dog
Random Page 7 NOT in P but still a member of V
Blah, blah, blah content; this can be anything.
- [ ] task x #number, #tree, #circle
- [ ] task f #frog, #water, #egg
- [ ] task k #apple, #cat, #leaf, #egg
- [ ] task n #road, #water, #sky
- [ ] task blah #shop, #gate, #surfboard, #sky
N.B. the last two page models do not have the dataview field attribute_A. So they don’t belong to P, but they do still belong to V. However, remember: we defined pages that have tasks on them as R. Whether a given page belongs to P or not is irrelevant for membership in R.
We have just modeled the pages in V that have tagged tasks, and we called this collection of pages R. Hopefully, these things are clear.
Tags
Please now swing your attention around to focus on tags.
So that we can deal with them easily, let’s treat the tags associated with a given task on a page in R in a similar way to how we treated the tags associated with attribute_A on pages in P: let’s give them a label too.
When it doesn’t matter which collection of tags associated with a task we find on a page in R, but we just want to talk about one of collections, let’s use the label t.
So far now we have two types of tag bunches: t and u.
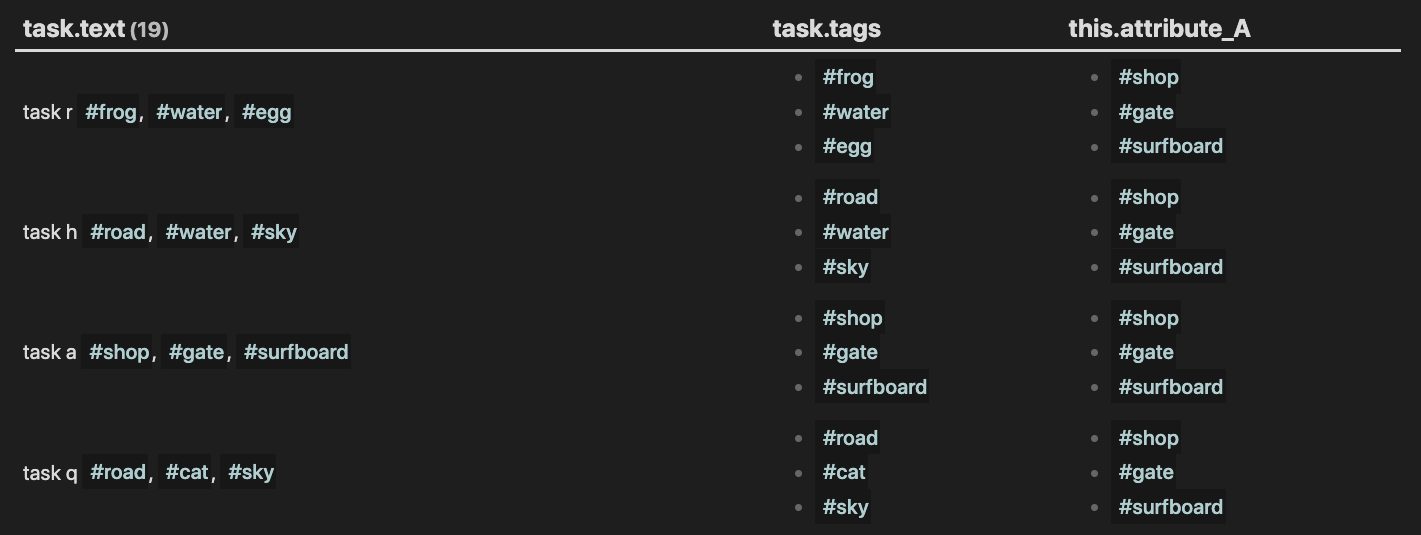
With these labels noted now you should see that sometimes t exactly matches u of attribute_A, and sometimes it doesn’t.
For example, the tags of - [ ] task l #apple, #cat, #leaf found on Random Page 6 exactly match those of attribute_A on Random Page 1 . However the tags of - [ ] task f #frog, #water, #egg do not exactly match any of the attribute_A fields in P. It’s true that there is tag that is found in attribute_A: The #water is found in Random Page 2. However not every tag in - [ ] task f #frog, #water, #egg is found together in an attribute_A of some page in P… sometimes t matches u… and sometimes it doesn’t.
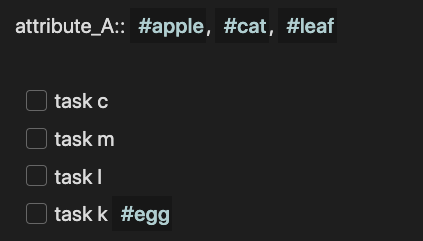
…and sometimes u is a subset of t. For example, we can see that the tags associated with attribute_A of Random Page 1 are a subset of those in - [ ] task k #apple, #cat, #leaf, #egg of Random Page 7: #apple, #cat, #leaf is clearly a subset of #apple, #cat, #leaf, #egg.
(Note: being A being subset of B means that B is the superset of A… this will worth recalling shortly)
And so…
Part 3
"Next comes the hard part…
I want to find the subset of tasks of T (let’s call it T') for which there is a page in P whose every tag in u of attribute_A has the following property: it belongs to a common bunch of tags associated with some task of T'."
This means… all the tagged tasks can be bundled together in a set we can simply call T. Let’s lift the tags featured in our modeled pages and list them together in a big stack to make this concrete:
- [ ] task r #frog, #water, #egg
- [ ] task h #road, #water, #sky
- [ ] task a #shop, #gate, #surfboard
- [ ] task q #road, #cat, #sky
- [ ] task w #shop, #gate, #surfboard
- [ ] task b #road, #water, #sky
- [ ] task c #apple, #cat, #leaf
- [ ] task y #shop, #gate, #surfboard
- [ ] task o #shop, #gate, #surfboard
- [ ] task m #apple, #cat, #leaf
- [ ] task t #wheel, #bird, #pencil
- [ ] task s #road, #water, #sky
- [ ] task l #apple, #cat, #leaf
- [ ] task z #person, #food, #dog
- [ ] task x #number, #tree, #circle
- [ ] task f #frog, #water, #egg
- [ ] task k #apple, #cat, #leaf, #egg
- [ ] task n #road, #water, #sky
- [ ] task blah #shop, #gate, #surfboard, #sky
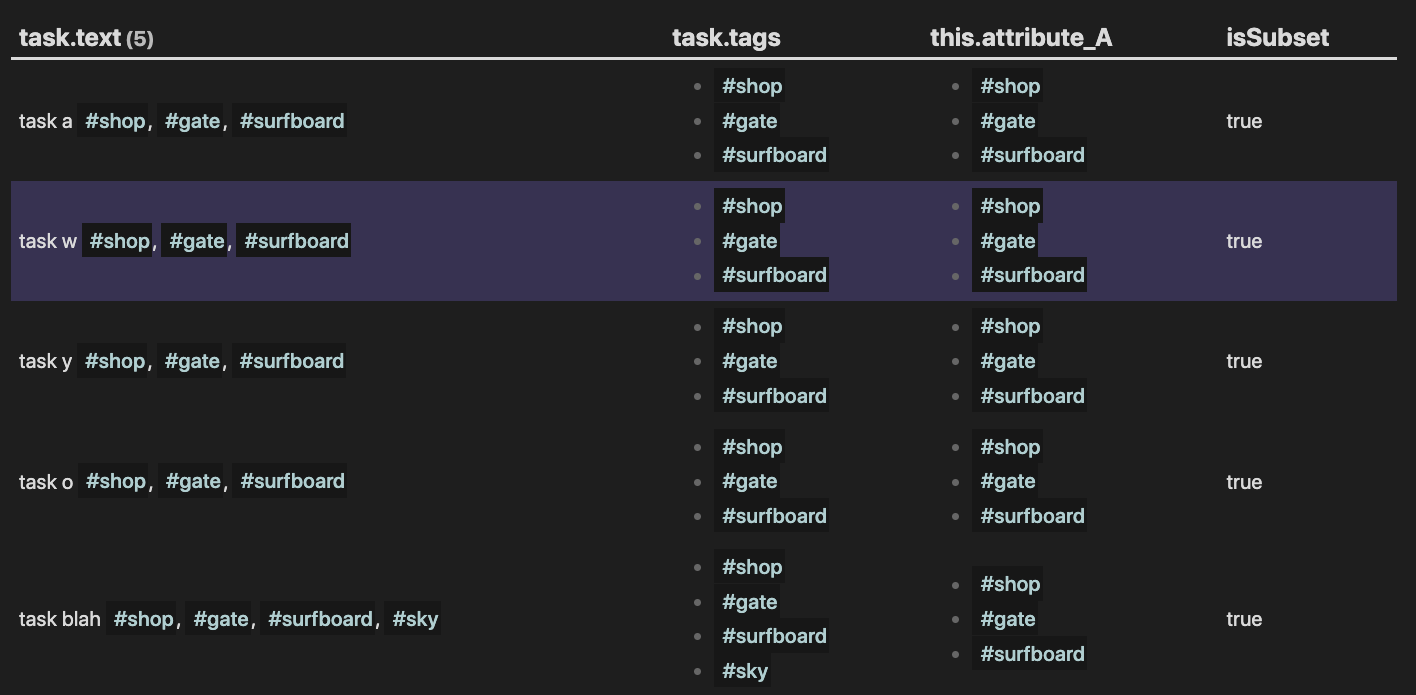
I’m looking for a subset of this set above (which we call T). Let’s agree that the subset I’m after is called T'.
T' has the following properties:
For every task in T' there is a page in P whose tags found in attribute_A are such that all of them belong to the bunch of tags associated with the task.
Stated as above, I think the logic of my goal is closer to how it would be stated in a computer program. However, put another way, we can say that I want to find the following tasks T':
- the tasks whose tags are either exactly the same as the bunch of tags of
attribute_A or their superset.
(Note: Set A being the superset of set B is equivalent to set B being a subset of A. )
I hope I have sufficiently unpacked the original post.
Thanks for your time and patience.
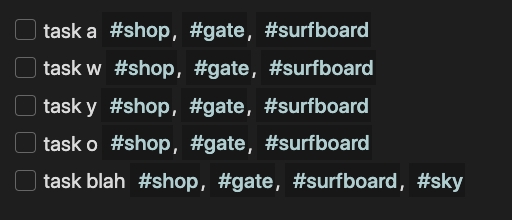
Additional Info
I didn’t specify this in the original post, but I’d like to group the tasks of T' under the heading of the pages in P whose set of attribute_A tags their tags are a superset of. Hopefully, I don’t have to unpack this additional info too… LOL