I’m not sure whether I was in a bad or good mood last night, but I started fiddling about with whether this was doable or not, and I came as far as this:
```dataview
TABLE WITHOUT ID
rows.month,
rows.rows.week,
rows.rows.file.name
FROM #f51737
GROUP BY month
GROUP BY rows.week
SORT rows.month
```
Which produces this output on my test data:
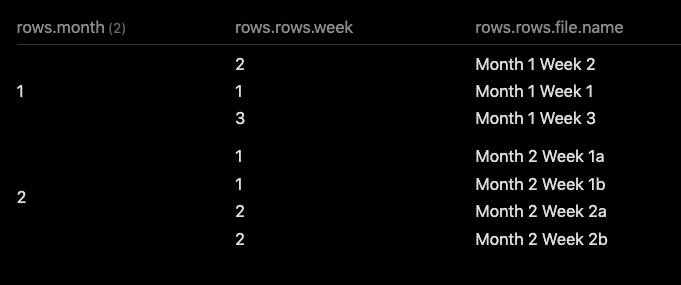
However, this produces the weekly results as lists within that table, but it does give the correct weeks and files available in my test set. Can we do better?!
I then came up with this monstrosity:
```dataview
TABLE WITHOUT ID
M, W, item.file.link
FROM #f51737
GROUP BY month
GROUP BY rows.rows.week
FLATTEN rows.month as M
FLATTEN rows.rows.week[0] as W
FLATTEN
filter(
rows.rows[0],
(F) => F.week = W AND F.month = M) as item
SORT item.file.link
```
Which gave this output:
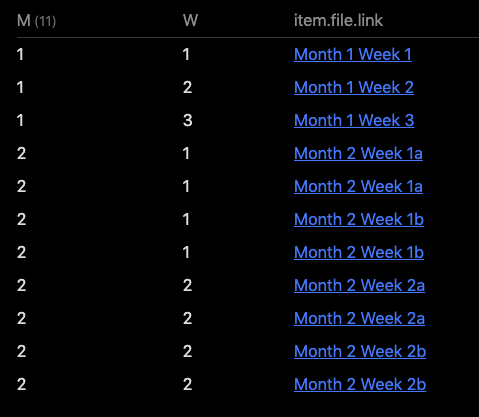
But there is something wrong with that last filter operation, see how it doubles up in month 2, week 2, where my test set had two files for each week.
One can insert item or rows.rows[0] (or rows.rows) into the table, to see available data, but I have so far not been able to single out just the correct bits and pieces.
And I’m also wondering if one actually needs yet another FLATTEN to be able to separate out individual file for a given month and week.
If anyone feel (strange? / up for it / …) please go ahead and tamper even more with this concept. I think I’m done for now.
Summary
It’s kind of doable using only dataview to do this double GROUP BY, but it gets messy, very fast, and it’s hard to process (at least for me ![]() ). And even if one would get the “correct” data set out of it, aka
). And even if one would get the “correct” data set out of it, aka month, week, "file object" you’re not anywhere near the correct formatting you originally wanted.
So in my book, go for the dataviewjs solution. It’s easy, and maintainable.