Like in add LIMIT 5?
Haha was it really that easy. I’m a total noob at this. Learning from scratch ![]() Thanks!
Thanks!
1 Like
Is there currently a better way to handle this?
(Btw, your snippet works like a charm, thank you for sharing this!)
I found a different statistics concerning word lengths: Distribution of Word Lengths in Various Languages - Ravi Parikh's Website
I’ve tried this solution and it doesn’t seem to work. I get zero values back yet when I manually substitute the full path I get the expected results.
My query is:
TABLE WITHOUT ID
file.link as "Subsectors"
from "Locations/Sectors/Core/Subsectors"
where type="subsector"
yet when I use the query:
TABLE WITHOUT ID
file.link as "Subsectors"
from "{{tp_folder:vault_path=true}}"
where type="subsector"
I get zero results. The file structure is:
Locations
Sectors.md
Sectors
Sector 1
Subsectors
Subsectors.md
Subsector 1
Subsector 1.md
World 1
World 1.md
img
img1.png
img1.png
Subsector 2
Sector 2
The markdown files are “index” files for the folders, FWIW, and get generated when a new sector/subsector/world is added (via the Buttons/QuickAdd plugins). I’m sort of stumped on how to get this working. :-/
Intro
This is my first post and I have never interacted in the forum (as you can see from my account…), yet I always find incredibly useful information on almost every post I read.
Since I’ve had this problem for such a while now, I wanted to post my solution also because I have never found useful code on the internet.
Probably my solution is not optimal, yet works for what I need.
Also: as you can maybe understand from my english, it is not my first language. So you will find some italian words in the code and maybe some grammatical error here and there… ![]()
AUTOMATIC TABLES DIVIDED BY TOPIC (ALSO WORKS FOR LIST OF TOPICS) IN DATAVIEWJS
Problem
I have a lot of programming note (about Python) that has the following YAML structure:
tags: 💾/esempio/python
languageVersion:
difficulty:
topic:
In the note I then include some other information such as Why i created this note, Coding technique used, Code snippet, Code output… But for us that is not important.
What matters is that I have some file with multiple topics! For example I have a note called Python - string into list in which the YAML is as following:
tags: 💾/esempio/python
languageVersion: all
difficulty: beginner
topic: [string, list]
When simply using the .groupBy(p => p.topic) in dataviewJs, such as following:
for (let group of dv.pages("#💾/esempio/python").groupBy(p => p.topic)) {
dv.header(3, group.key);
dv.table(["Esempio", "Topic", "Versione", "Difficoltà"],
group.rows
.sort(k => k.file.name, 'desc')
.map(k => [k.file.link, k["topic"], k["languageVersion"], k["difficulty"]])
)
}
The result comes as (trimmed for space):
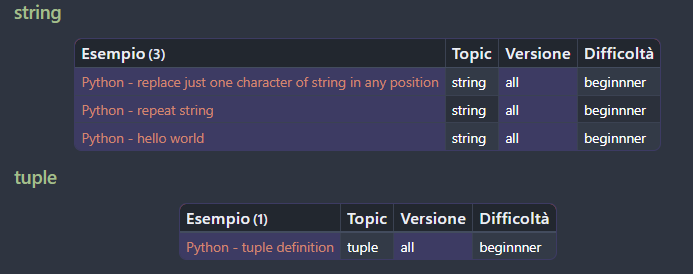
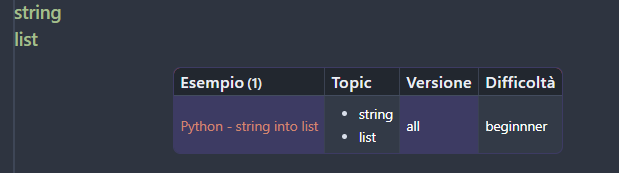
where the file Python - string into list is inserted in a table under another topic:
Solution
After having lost couple of hours searching for some useful code online, i decided to write it myself.
The idea behind it is to first create an array with single topic as entry, then print tables of files (not very different from the above code) containing single element of the array in the topic entry of YAML:
let tag = "#💾/esempio/python"
// **** DATA ARRAY WITH NON REPEATING TOPIC****
// Every element of array is a single topic
// It contains all the entry of 'topic' inserted in all the notes (so, with repetition)
let topics = dv.pages(tag).topic
// *****************************************************
// CREATE ARRAY WITH SINGLE TOPIC AS ELEMENT SUCH THAT THERE IS NO REPETITION
// *****************************************************
let listTopic = []
for (let topic of topics){
//dv.header(1, topic)
//dv.header(2, "--")
if (!listTopic.includes(topic)){
listTopic.push(topic)
}
}
listTopic.sort()
//dv.header(1,listTopic)
// *******************************
// PRINT TABLES OF FILES THAT CONTAINS SINGLE TOPIC IN THE 'topic' ENTRY
// *******************************
// As header is printed the topic, as table all the file containing that topic
let pages = dv.pages(tag)
for (let index of listTopic){
dv.header(3, index);
let pagesIndexed = dv.pages(tag).where(p => (p.topic).includes(index))
dv.table(["Esempio", "Topic", "Versione", "Difficoltà"],
pagesIndexed.sort(k => k.file.name, 'asc')
.map(k => [k.file.link, k["topic"], k["languageVersion"], k["difficulty"]])
)
}
The result is pretty nice:
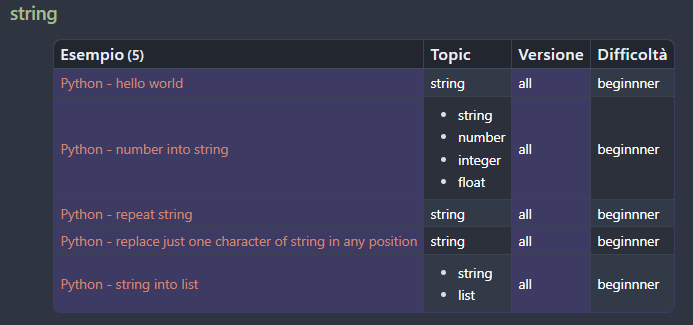
Conclusion
Probably my code has some imprecisions, and I welcome every tips about that.
Also I still am unsure if that is a problem never solved on the internet. I’ve lost lots of time searching for even partial solution but couldn’t find nothing. If that isn’t the case, let me know.
5 Likes
I am trying to get Dataview to show me tasks that have started in the last 30 days and are due within the next 30 days and are not done. I am having trouble getting any results. This is what I have tried at the moment.
task
From "Tasks/Home Tasks"
Where start < 30 days ago and due > 30 days
Could anyone help please?
Messing around with chatGPT’s code generation and had it generate a tag-cloud code using only dataviewjs and standard javascript. Took a bit of fiddling and about 4 hours of work but that is much quicker then I could have done this by hand…
Lists all files and tags, except those in the excluded paths. Determines size and color based on filename, number of tags, and word count (ignoring metadata, code blocks, and latex blocks. It also randomizes the order for good effect. Clicking on a file will open the file, clicking on tags does nothing but could be fixed if you feel like it.

const FromStr = `-"00 meta" AND -"50 logs"`;
const filesQuery = dv.pages(FromStr);
async function backlinksQuery(query) {
const file = query.split('/').pop().split(".").slice(0, -1).join(".");
return dv.query(
`
LIST
FROM [[${file}]] AND ${FromStr}
`
);
}
/* Dataview query to retrieve all tags and their associated .md files */
async function tagsQuery(query) {
return dv.query(
`
LIST
FROM "${query}"
where tags != ""
`);
}
async function tagFilesQuery(query) {
return dv.query(
`
LIST
FROM ${FromStr}
where tags = "${query}"
`);
}
/* Dataview query to retrieve the number of words in each .md file */
async function wordCountQuery(query) {
const fs = require('fs');
const path = require('path');
const text = fs.readFileSync(path.join(app.vault.adapter.basePath, query), 'utf-8');
// remove blocks
const pattern = /---[\s\S]*?---|```[\s\S]*?```|\$[\s\S]*?\$|\$\$[\s\S]*?\$\$/g;
const cleanedText = text.replace(pattern, '');
// count words
return cleanedText.match(/\S+/g).length;
}
/* Function to calculate the font size for each tag based on the number of backlinks and number of words */
function calculateFontSize(backlinks, wordCount) {
const backlinksWeight = 0.2;
const wordCountWeight = 0.8;
const maxFontSize = 24;
const minFontSize = 8;
const fontSize = Math.sqrt((backlinks * backlinksWeight) + (wordCount * wordCountWeight)) * 4;
return Math.round((fontSize / 100) * (maxFontSize - minFontSize) + minFontSize);
}
/* Function to calculate the color for each tag based on its name */
function calculateColor(tagName) {
if (tagName == null) {return "#FFFFFF";}
const colors = {
"red": "#ff6464",
"orange": "#ffb364",
"yellow": "#ffd664",
"green": "#64ff64",
"blue": "#64bfff",
"purple": "#b864ff",
"ruby-red": "#D62E4D",
"sunny-yellow": "#F6C026",
"vivid-orange": "#FF6E1F",
"bright-pink": "#F1478A",
"electric-blue": "#0F7DC2",
"deep-purple": "#5B0F91",
"teal-green": "#007F86",
"golden-brown": "#AA8F6A",
"moss-green": "#8BC34A",
"navy-blue": "#3F51B5",
"pale-pink": "#F7B1B1",
"soft-lilac": "#C9A1E9",
"pastel-green": "#B3E6C3",
"sky-blue": "#87CEEB",
"light-gray": "#D3D3D3",
"chocolate-brown": "#5F4B32",
"cream-yellow": "#FFFDD0",
"peach-orange": "#FFCC99",
"dusty-rose": "#C4A4A4",
"seafoam-green": "#71BC9C"
};
const tagWords = tagName.split(/\W+/g);
const colorIndex = tagWords.reduce((total, word) => total + word.charCodeAt(0), 0) % Object.keys(colors).length;
return colors[Object.keys(colors)[colorIndex]];
}
function shuffleArray(arr) {
for (let i = arr.length - 1; i > 0; i--) {
const j = Math.floor(Math.random() * (i + 1));
[arr[i], arr[j]] = [arr[j], arr[i]];
}
return arr;
}
// tagData.push(fileData)
/* Create the HTML for the tag cloud */
const tagCloudHtml = async () => {
const tags = new Map();
const files = new Map();
/* Add all .md files to the tags map with their backlinks and word count */
Promise.all(filesQuery.map(async (f) => {
const file = f.file
const blq = backlinksQuery(file.path)
const wcq = wordCountQuery(file.path)
if (file.tags) {
await Promise.all(file.tags.map(async (tag) => {
if (!tags.has(tag)) {
tags.set(tag, { backlinks: 0, wordCount: 0 });
}
const tagInfo = tags.get(tag);
const res = await blq;
tagInfo.backlinks += res.value.values.length;
const wc = await wcq;
tagInfo.wordCount += wc;
}));
}
const fileInfo = { backlinks: 0, wordCount: 0 };
const res = await blq;
fileInfo.backlinks = res.value.values.length;
const wc = await wcq;
fileInfo.wordCount = wc;
files.set(file, fileInfo);
}))
.then(() => {
const data = []
/* Calculate the font size, color, and shape for each tag */
tags.forEach((tagInfo, tagName) => {
const fontSize = calculateFontSize(tagInfo.backlinks, tagInfo.wordCount);
const color = calculateColor(tagName);
data.push({ name: `\\${tagName}`, fontSize, color });
});
/* Calculate the font size, color, and shape for each file */
files.forEach((fileInfo, fileName) => {
if (fileName == null) {return;}
const fontSize = calculateFontSize(fileInfo.backlinks, fileInfo.wordCount);
const color = calculateColor(fileName.name);
data.push({ name: fileName.name, fontSize, color});
});
return shuffleArray(data).map((tag) => {
return `<a class="tag-cloud-anchor" href="obsidian://open?vault=OBSIDIAN-VAULT&file=${encodeURIComponent(tag.name)}" style="font-size:${tag.fontSize}px; background-color: #4444444f; color: ${tag.color};">${tag.name}</a>`;
}).join("");
}).then(res => dv.paragraph(res))
.catch(error => {
console.error(error);
});
}
tagCloudHtml()
10 Likes
Hi, I want to list all files that link to my current note.
LIST
FROM [[]] AND #zettel
WHERE
contains(source, this.file.link)
AND "Permanent notes"
and it works fine, but only display files that link to the whole file, but not to a block of that file.
It lists files that have:
source:: [[The Book]]
But not the ones that have
source:: [[The Book#^3cd5dd]]
What do I need to change in that query to get a list of files that link to the whole file OR to a block in that file?
1 Like
Someone else asked a similar question, and then I found this post, and a hack to provide a solution for you as well.
The trick/hack is to use regexreplace() to insert the thousand separator. So do something like the below to achieve the output. I suggest keeping the numbers as numbers, so you can keep using them for calculations.
`= regexreplace("1234567.12", "\B(?=(\d{3})+(?!\d))", ",") `
TABLE regexreplace(someNumberField, "\B(?=(\d{3})+(?!\d))", ",") as "nice number"
....
Hope this helps, and that you’re still in search for this answer… ![]()
1 Like
List Birthdays within next 30 days (sticking to pure dataview)
If you’re like me preferring pure dataview snippets without using js too much this one might be of interest to you. ![]()
Snippet will show you a list of persons celebrating birthday within next 30 days.
Prerequisite
Ideally you have a list of persons (e.g. VAULT/FAMILY/PERSONS … person1.md, person2.md …). These person-files need to have a YAML entry containing the next birthday:
nextbday: 2023-12-24
To display the list add following snippet to where you want it to be shown:
```dataview
LIST nextbday + " (in " + (round(dur(date("today") - nextbday).day) * (-1)) + " Tagen)"
FROM "ARBEIT/PERSONEN"
WHERE (round(dur(date("today") - nextbday).day) * (-1)) <= 30
SORT nextbday ASC
Just localize for yourself.
Don’t forget to update the field after celebration is done … ![]()
2 Likes
Aaaah … too late to edit.
An example I forgot to add:
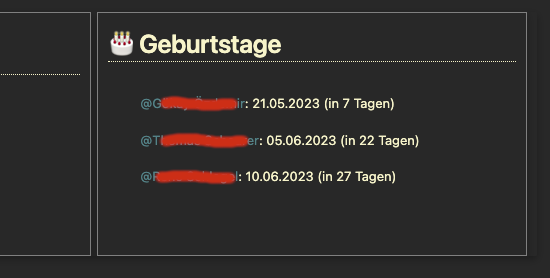
A variant of your script which would eliminate the double calculation of the days, and avoid the negative multiplication would be:
```dataview
LIST nextbday + " (in " + dayCount + " Tagen)"
FROM "ARBEIT/PERSONEN"
FLATTEN round(dur(nextbday - date("today")).day) as dayCount
WHERE dayCount <= 30
SORT nextbday ASC
```
Update: For a different approach regarding next birthday, see
1 Like
Thank you holroy for your reply. For your approach it is necessary no YAML/nextbday is empty (in my case I don’t know the bdates of all my tracked persons). Otherwise you will get all the empty fields as additional result. Tried to work around with some default() attempts but failed. I am sure I overlooked something. ![]()
Do you require the nextbday to be present, and how do you want it handled when they’re not present?
Well, going with the initial script I posted empty nextbday fields simply are ignored - which is good in this case (there are other cases I really wished there would be something like a left outer join ![]() ). I think that’s because of the first calculation finding no value.
). I think that’s because of the first calculation finding no value.
Long story short - empty fields (nextbday)should be ignored / not calculated. I tried that birthday js you posted in addition but for my taste and use it’s much too much. That’s because I tried that “simplier” way …
I failed to address the simple ignoring of your initial query when no nextbday was present, so to correct that just change to WHERE nextbday AND dayCount < 30 in my version, and you’ll get the same output. And that is also including mentioning birthdays of guys in the past or some days ago…
With this correction the full query is:
```dataview
LIST nextbday + " (in " + dayCount + " Tagen)"
FROM "ARBEIT/PERSONEN"
FLATTEN round(dur(nextbday - date("today")).day) as dayCount
WHERE nextbday and dayCount <= 30
SORT nextbday ASC
```
To compensate for the strangeness I’ve introduced you to by omitting the nextbday in the WHERE clause, I’ve also taken the liberty to extend your script to replace the year of nextbday with current year, so that you can keep running this query over and over again (year after year):
```dataview
LIST currbday + " (in " + dayCount + " Tagen) "
FROM "ARBEIT/PERSONEN"
FLATTEN date(today) as today
FLATTEN date(today.year + substring(string(nextbday), 4)) as currbday
FLATTEN round(dur(currbday - today).day) as dayCount
WHERE nextbday AND dayCount > -4 AND dayCount <= 30
SORT nextbday ASC
```
This version also includes a configurable number of birthdays in the last few days, just in case you’ve forgotten it. Adjust to your liking how many days you’d like to keep remembering old birthdays.
Using this last variant of the script, you could actually change the nextbday to the actual birthdate (with correct birthyear) of the person in question, and add stuff like + (currbday.year - today.year) + " Jahre alt" to show you how old they will become.
Update: Changed away from test folder setup using file.folder = this.file.folder
1 Like
Thank you for all your efforts holroy. You are impressing with shooting your ideas like a machine gun. ![]()
First script now runs like a charm:
Upcoming Birthdays
- @Professor Snuggles: 20.05.2023 (in 5 Tagen)
- @Captain Future: 05.06.2023 (in 21 Tagen)
The second one (your goodie especially for me ![]() thank you again!) don’t want to do as told. Results from “as it is” stays empty. For investigation I tried to do some changes:
thank you again!) don’t want to do as told. Results from “as it is” stays empty. For investigation I tried to do some changes:
cut out
WHERE nextbday AND dayCount > -4 AND dayCount <= 30
Result:
- Dashboard: – (in – Tagen)
- Monat 2023 Woche 20: – (in – Tagen)
- PKM: – (in – Tagen)
… and many more
change from above + changed
WHERE file.folder = this.file.foldertoFROM "110 PERSONEN2"
Result:
- @Professor Snuggles: – (in – Tagen)
- @Captain Future: – (in – Tagen)
- @Time Lord: – (in – Tagen)
- @Doctor Past: – (in – Tagen)
I suspect the substring to be the guilty one. Dataview don’t like that fooling around with strings …
I use nested tags like #i/DDMDCEKW/123 to mark source of tasks, where DDMDCEKW refers to the source item and 123 refers to the source page.
So i can use this snippet to show all task from the same item and sort by pages.
task
where contains(tags, "#i/DDMDCEKW")
sort filter(tags, (t) => regexmatch("#i/DDMDCEKW/\d+", t))
group by file.name
2 Likes
Dataviewjs help! almost the same query used in templater and in a simple note but the results are different
dv.taskList(dv.pages().file.tasks
.where(t => !t.completed)
.where(t => t.text.includes("2023-06-23")))
this query returns correctly, but when I change “2023-06-23” with today’s date, like: date(today)
but it always returns empty result… I thought it was just a simple snippet but it took me days without any progress, I don’t have any coding background so I had to call for help here…
1 Like
exactly what i needed! thank you!