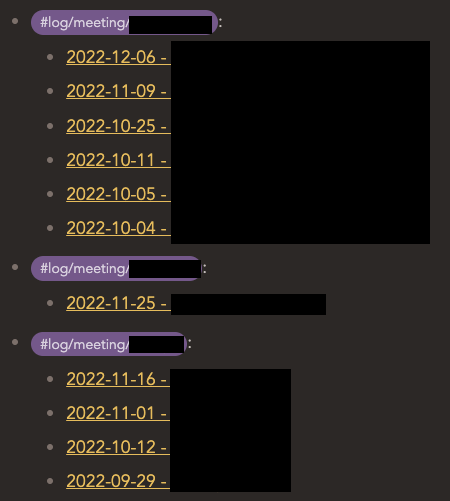
I’m trying to list out my most recent meetings grouped by nested meeting tags.
I want my 5 most recent meetings per-group to be shown.
Things I have tried
This is my current query:
LIST rows.file.link
FROM "Calendar/09 Meetings" AND -#on/readme
FLATTEN file.etags AS Tags
WHERE contains(Tags, "#log/meeting/")
GROUP BY Tags
SORT rows.file.name DESC
This shows all my meetings under each tag. I’ve tried putting LIMIT 5 under FROM which only shows 5 file rows regardless of the tag. Putting LIMIT 5 under the tag section only limits the nested tag ‘headers’ that the files are grouped by.
I guess this query type requires dvjs (but I don’t know how to do it).
But you can explore this very, very tricky way:
LIST filter(map([0,1,2,3,4], (x) => rows.file.link[x]), (m) => m)
FROM "Calendar/09 Meetings" AND -#on/readme
FLATTEN file.etags AS Tags
WHERE contains(Tags, "#log/meeting/")
SORT file.name DESC
GROUP BY Tags
SORT Tags ASC
This is using a dataviewjs query, and picks out one element each time the filename changes. You should be able to use the same kind of logic to achieve your goal. You would change my code so that it triggers picking out links each time the Tags changes, and then instead of just picking one, you could pick up to 5 files.
The latter could be achieved by having a counter of how many you’ve picked alongside the prevPath (or in your case the prevTag). For each time you push a file to the list, you’ll increment the counter. If the counter is too high before you push, you don’t push, and if the tag changes you reset the counter.
I hope this is enough information for you to get going, as I’m not able to build a test case based on your information, and I’m a little busy to rework the script just now. If you give it a go and change my script, you could post your work, and I could review at a later time.
A pure dataview solution?
I’m not sure if, or how, it’s doable without using dataviewjs, but I was contemplating on whether it’s possible to build a where clause, where you check the current rows element index value, and check whether that index value is below your threshold.
The question here would then be, do we have access to the current index value of a row? Do you know that, @mnvwvnm?
As far as I know, there is not any similar indexOf() in dql. That’s why I suggested the tricky way in my last post - map([0,1,2,3,4], (x) => rows.file.link[x]) -, defining the wanted rows by the index number. (filter will exclude the “null” cases).