Even tho the last reply is a bit older, I felt like sharing my solution in case anyone stumbles across this thread.
I created a DataviewJs Script inspired by Meastn’s Design. The difference between the Dataview DQL Queries provided by @Edmund and @statmonkey is that my Query includes some parts of the note. This obviously comes with some performance downsides since the note contents have to be fetched. However now I don’t have to write my Definition as metadata but just have it in the note content.
The resulting glossary looks like this: (Theme: Encore, with some custom CSS snippets)
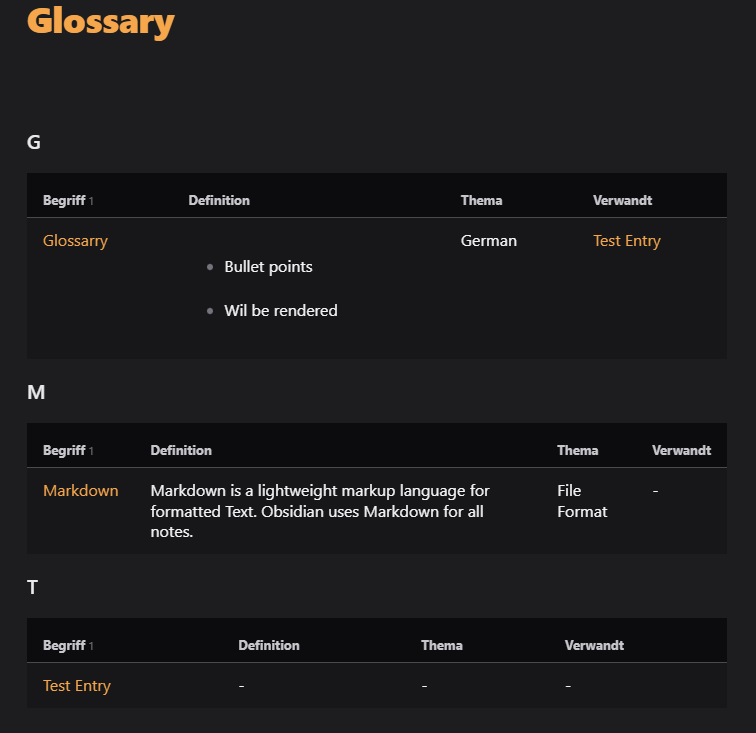
A note for a glossary entry could look like this:
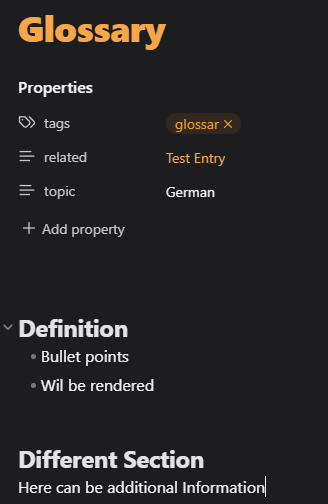
My Frontmatter looks like this:
---
tags:
- "#glossar"
related: "[[Test Entry]]"
topic: German
---
The DataviewJs Script I am using might be a bit bloated and could be written simpler, but this is what I am working with. I tried to add enough comments so that it’s clear even for inexperienced JS users.
// Define custom values
const tagName = "#glossar";
const mySectionName = "Definition";
/**
* Returns a substring of the given markDownstring which will be the content of the
* given section. Leading and trailing spaces will be trimmed.
* The markdownstring should include the given sectionName with 1 to 5 (both inclusive)
* hashtags in front with optional spaces in between. The section with the given
* sectionName may be the last section in the markDownString.
* @param markDownString a markdown formatteed string which contains the section to be searched for
* @param sectionName the name of the section to be searched for in the markDownString
* @returns a substring of the markdownstring which is exactly the searched for section content (spaces trimmes)
* or if the given section is not found: "<span>-</span>"
*/
const getSectionContent = (markDownString, sectionName) => {
// match between 1 to 5 hashtags and optional spaces before the sectionName
const sectionPattern = new RegExp("#{1,5}\\s*" + sectionName);
// match between 1 to 5 hashtags
const nextSectionPattern = new RegExp("#{1,5}");
// check if sectionName can be found in the markDownString
let sectionHeaderLength;
if (sectionPattern.test(markDownString)) {
sectionHeaderLength = markDownString.match(sectionPattern)[0].length;
} else {
return "<span>-</span> "; // break with custom string since section not found
}
const startingIndex = markDownString.search(sectionPattern);
// search for a next section starting after the found sectionName
const endingIndex = markDownString.substring(startingIndex + sectionHeaderLength)
.search(nextSectionPattern);
// Check if a next section exists or end of string has been reached
if (endingIndex == -1) {
return markDownString.substring(startingIndex + sectionHeaderLength).trim();
} else {
return markDownString.substring(
startingIndex + sectionHeaderLength, // remove the section header
startingIndex + sectionHeaderLength + endingIndex // add starting point since endingIndex is determined of substring
);
}
};
// == Render a table for each starting character ==
// group all notes with tag #glossar by the first character of the note file name
const groupedTableEntries = dv.pages(tagName).groupBy(note => note.file.name.charAt(0).toUpperCase());
for (let group of groupedTableEntries) {
const tableEntries = await Promise.all(
group.rows // all entries for the current group aka current table
.map(async (note) => {
const content = await dv.io.load(note.file.path); // load the note content
// map pages to custom object which contains all needed data
return {
name: note.file.name,
link: note.file.link,
definition: getSectionContent(content, mySectionName), // get the section content
topic: note.topic,
related: note.related
};
})
);
dv.header(3, group.key); // show the character as the header
dv.table(["Begriff", "Definition","Thema", "Verwandt"],
tableEntries
.sort((entryA, entryB) => entryA.name.localeCompare(entryB.name))
.map(entry => [entry.link, entry.definition, entry.topic, entry.related])
)
}
The script is inspired by S-Blu Github Pages, the Dataviews Codeblock Examples and this Post in a Showcase Thread