Steps to reproduce:
Copy and paste 字体_斜体_字体*斜体*字体
Actual result:

Expected:

Steps to reproduce:
Copy and paste 字体_斜体_字体*斜体*字体
Actual result:
Expected:
The problem is with the Reader, your actual result is correct. I edited the title to reflect where the problem is.
https://spec.commonmark.org/0.30/#emphasis-and-strong-emphasis
Hi,
The “actual result” was the result from live preview, and the “expected” was the result from reading mode and the output file. The two results are inconsistent.
The two results are inconsistent. I guess the two modes use different parsers. You can say this is not a bug for its specific implementation, but I consider the inconsistency a bug.
And btw do you consider this a bug?
Copy and paste 啦。**啦。**啦。
The result in live preview:

From the website you cited, “Many implementations have also restricted intraword emphasis to the * forms”, so the asterisks here should work, right?
According to commonmark spec, The bug is in the reader, non LP.
This is a whole other can of worms related to how markdown should handle Chinese special punctuation characters.
How about not making the full stop bold?
啦。啦。啦。
啦。**啦**。啦。
Or using a zero-width space after the full stop (not sure if that will copy and paste here correctly)? Both parse.
啦。啦。啦。
啦。**啦。**啦。
Hi,
Thank you. These are good workarounds!
btw, how did you type that zero-width space?
On macOS: Edit → Emoji & Symbols → insert the zero-width space.
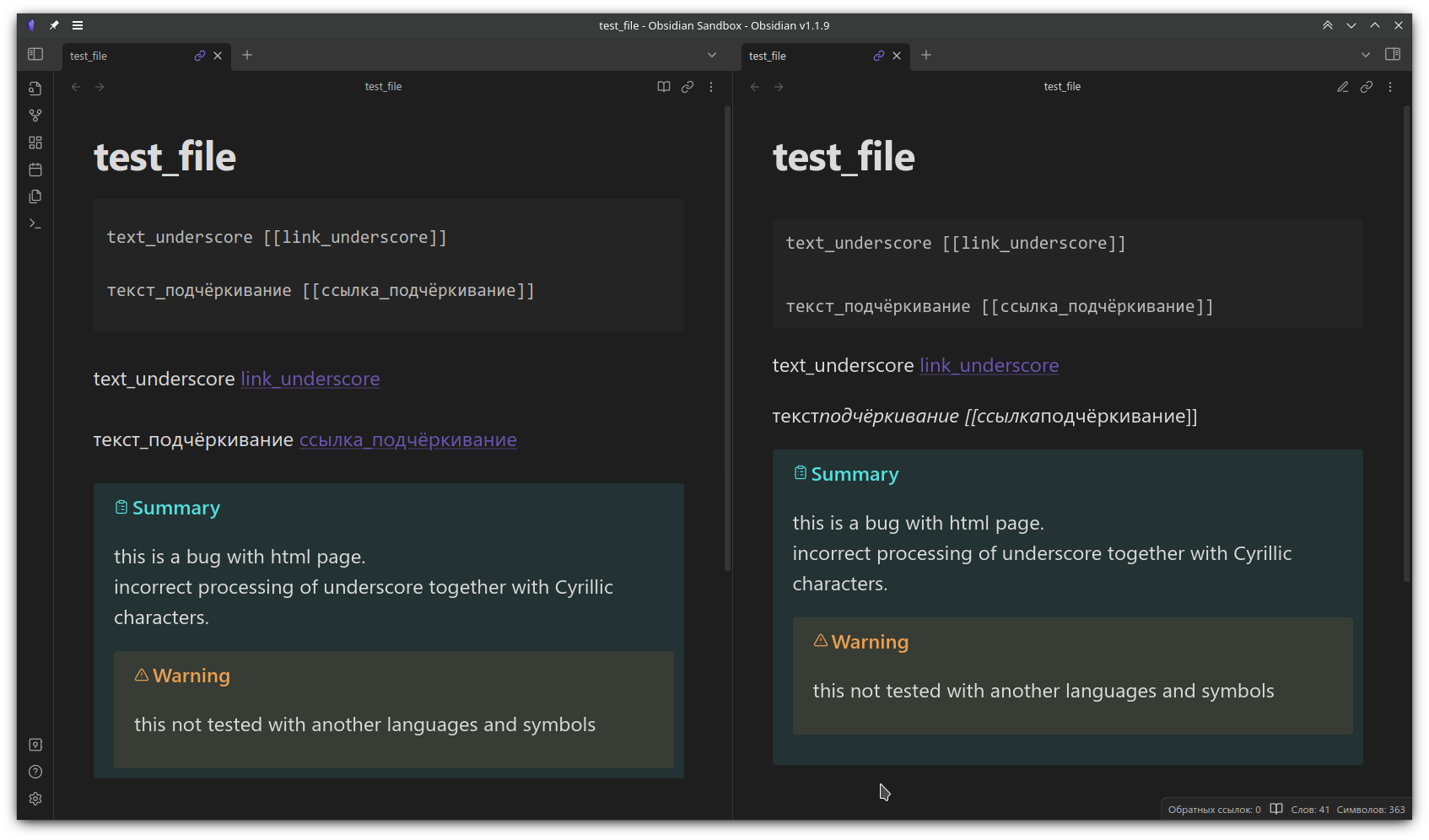
underscore do not work correctly with cyrilic symbols and broke links in preview mode.
in line-preview it works correctly
enter text and link with underscore
for example:
текст_подчёркивание [[текст_ссылка]]
see what happens in preview mode
working link to note текст_ссылка in preview
preview do not work correctly
SYSTEM INFO:
Obsidian version: v1.1.9
Installer version: v1.1.9
Operating system: #1 SMP PREEMPT_DYNAMIC Mon Feb 6 11:26:13 UTC 2023 6.0.19-4-MANJARO
Login status: not logged in
Insider build toggle: off
Live preview: on
Legacy editor: off
Base theme: dark
Community theme: none
Snippets enabled: 0
Restricted mode: on
example on sandbox vault
this problem works on desktop client
on mobile this not happens.
I am sure it happens too.
i was test that
links are not broken on android client. they only formatting to be italic
live-preview
preview:
You are not separating with a blank line on mobile.
This is source mode
[[A_20230515132631_B]]
[A_20230515132631_B](A_20230515132631_B.md)
[[文字_20230515132631_文字]]
[文字_20230515132631_文字](文字_20230515132631_文字.md)
This is reading mode,it’s wrong.

This is reading mode,it’s right.

Using [] () this form of a link, if the file name is like the fourth line-----the Chinese characters are next to _, then in the Reading mode, it will be rendered as an oblique body, which is incorrect. but in live preview mode, it’s normal.
The _ is the delimiter of the file name. Normally, it should be like the first, second and third lines, and should not be rendered as italics.
Hope to repair this problem,or let the user choose to disable the unnecessary MD syntax. For example, I don’t usually use _, I usually use *
_ is useless and produces the above errors