Hi y’all—
I’m here today to talk about library and information science (LIS), personal knowledge management (PKM), and YOU.

Since this whole PKM/B (base) thing has taken off there has been endless endless endless discussion on how to organize things. Systems seem to pop up all the time ranging from PARA to Johnny Decimal, to folksonomies, etc, etc. This is a really fascinating and interesting time to be around and also very exciting to see this developing. however one thing that gets lost in all of these back and forth and arguments is that there is an entire field dedicated to the representation organization cataloging and classification of knowledge, a field that has been around for hundreds of years & has the experience of thousands of people involved: library and information science.
As far as I’m able to discern, almost none of these novel PKM or PKB organization systems have benefited from the input of library and information science. There are a lot of things that the LIS field can provide to help all y’all PKM folks. I’m going to talk about that a bit below.
But why should you trust me? What are my qualifications? Both of these are fair questions! My name is Brian M. Watson (here is my twitter: https://twitter.com/brimwats). I’m a PhD. student at the University of British Columbia’s School of Information (aka the iSchool). I study equitable cataloging in Galleries, Archives, Libraries, Museums, and Special Collections (GLAMS), and I have a Masters in Library Science from Indiana University Bloomington where I studied metadata and digital humanities. I also have a MA from Drew University focusing on the history of the book and sexuality.
In other words, I study how people organize stuff and how institutions can do that in a more ethical manner. But that’s not what I’m here for today. Today I’m going to talk about my system
Definitions
First, some definitions:
classification, n.
Origin: A borrowing from Latin. Etymon: Latin classificatio.
Etymology: < post-classical Latin classificatio (1673 in a German source; 1767 in Linnaeus) < classical Latin classis class n. + -ficātiōn- , -ficātiō
- The result of classifying; a systematic distribution, allocation, or arrangement of things in a number of distinct classes, according to shared characteristics or perceived or deduced affinities. Also: a system or method for classifying.
- The action of classifying or arranging in classes, according to shared characteristics or perceived affinities; assignment to an appropriate class or classes.
catalogue, n.
Etymology: < French catalogue, and < late Latin catalogus, < Greek κατάλογος register, list, catalogue, < καταλέγειν to choose, pick out, enlist, enroll, reckon in a list, etc., < κατά down + λέγειν to pick, choose, reckon up, etc
- A list, register, or complete enumeration; in this simple sense now Obsolete or archaic.
- Now usually distinguished from a mere list or enumeration, by systematic or methodical arrangement, alphabetical or other order, and often by the addition of brief particulars, descriptive, or aiding identification, indicative of locality, position, date, price, or the like.
Simply put: classification is where things go, either on a shelf or in a computer system and so on. More information.
Cataloging is what we call things, the subject headings, aliases or tags, we give them. More information.
Cataloging often has things called controlled vocabularies. Controlled vocabularies often look something like this

(this is from the Library of Congress Subject headings: Library of Congress Subject Headings PDF Files).
If you want more information on a thesaurus take a look at this blog I wrote: Internship Diaries #3: Thesaurasize Me, Captain – bloggings & musings
When I see things like Maps of Contents with with tag definitions I am seeing a controlled vocabulary a hop and skip away from a hierarchical classification system.
An uncontrolled vocabulary is much more like chaotic tagging systems like you’d see on librarything (or perhaps your poorly organized PKM ![]() )
)
Tagging is very useful but the lack of control and meaning breaks things down fast.
“a (controlled term) is worth a thousand tags” as one article put it.
Part of my pitch here is to say that i8n organizing your PKB you should favor controlled vocabularies and favor classification systems when you can.
But I am not here to preach. If you don’t want it or if it’s not for you, that’s fine. What I am going to do below is talk about my own system that I’ve designed over months to fit my PKB needs.
The Decimal-Cutter PKB System
This system derives inspiration from the following major systems: PARA, Johnny Decimal, Universal Decimal Classification. and Cutter Expansive Classification. I also take inspiration from Nick Milo’s LYT Kit, color theory, Library of Congress Classification, Bliss Classification, Universial Decimal
PARA
From PARA I take the advice that a digital system should be:
- cross-platform, able to be used with any application, now existing or yet to be developed
- outcome-oriented, structuring information in a way that supports the delivery of valuable work
- flexible, able to work with any project or activity you take on, now and in the future
- universal, encompassing any conceivable kind of information from any source
I also take some inspiration from the the PARA (Projects — Areas — Resources — Archives) idea. For Tiago these are:
A project is “a series of tasks linked to a goal, with a deadline.”
An area of responsibility is “a sphere of activity with a standard to be maintained over time.”
A resource is “a topic or theme of ongoing interest.”
Archives include “inactive items from the other three categories.”
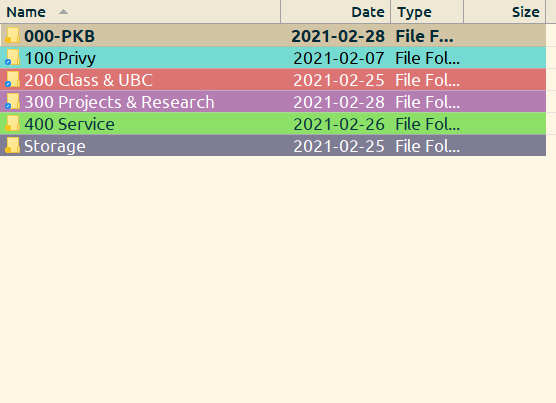
I riff on these with my top-level file organization:

I use Directory Opus in windows to tag certain areas with colors. The colors are similar across my Zotero, my Airtable, my Google Calendar, and my files. This means I can tell with one glance what area of my life it comes from.
In the rest of this we are just focusing on the PKB Folder.
Johnny Decimal
- Johnny Noble’s Johnny Decimal
I take the structure of numbering (classification) from Johnny Decimal.
Specifically, Step one:
Step 1: Divide everything in to ten things
- Take everything you need to organise and sort it in to, at most, ten large buckets.
- Make sure the buckets are unambiguously different.
- Put a label on each bucket.
This forces you to group things quite broadly, but that’s the point.
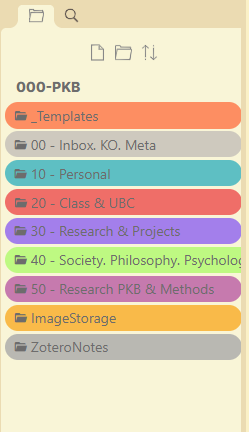
which you can see here
I will explain the titles in a second. Each of these subfolders are also numbered as in JD.
Before the decimal: category
The decimal point is there to break the number up, but more importantly to remind you that the number before the decimal is the important part. It’s the category.
After the decimal: ID
The number after the decimal is just a counter. We call it the ID: it starts at .01 and increases with each thing you create.
Zotero PARA Sidebar
But I don’t do it in numerical order. But remember PARA? This system should apply elsewhere! Like my zotero!

Admittedly, much of this is still under construction so the category numbers are not there yet. They will be eventually!
As a sidebar, you can see what the point of each hilight color in my zotero is (also connected to my folder colors + color theory but I just include this as a data point.)


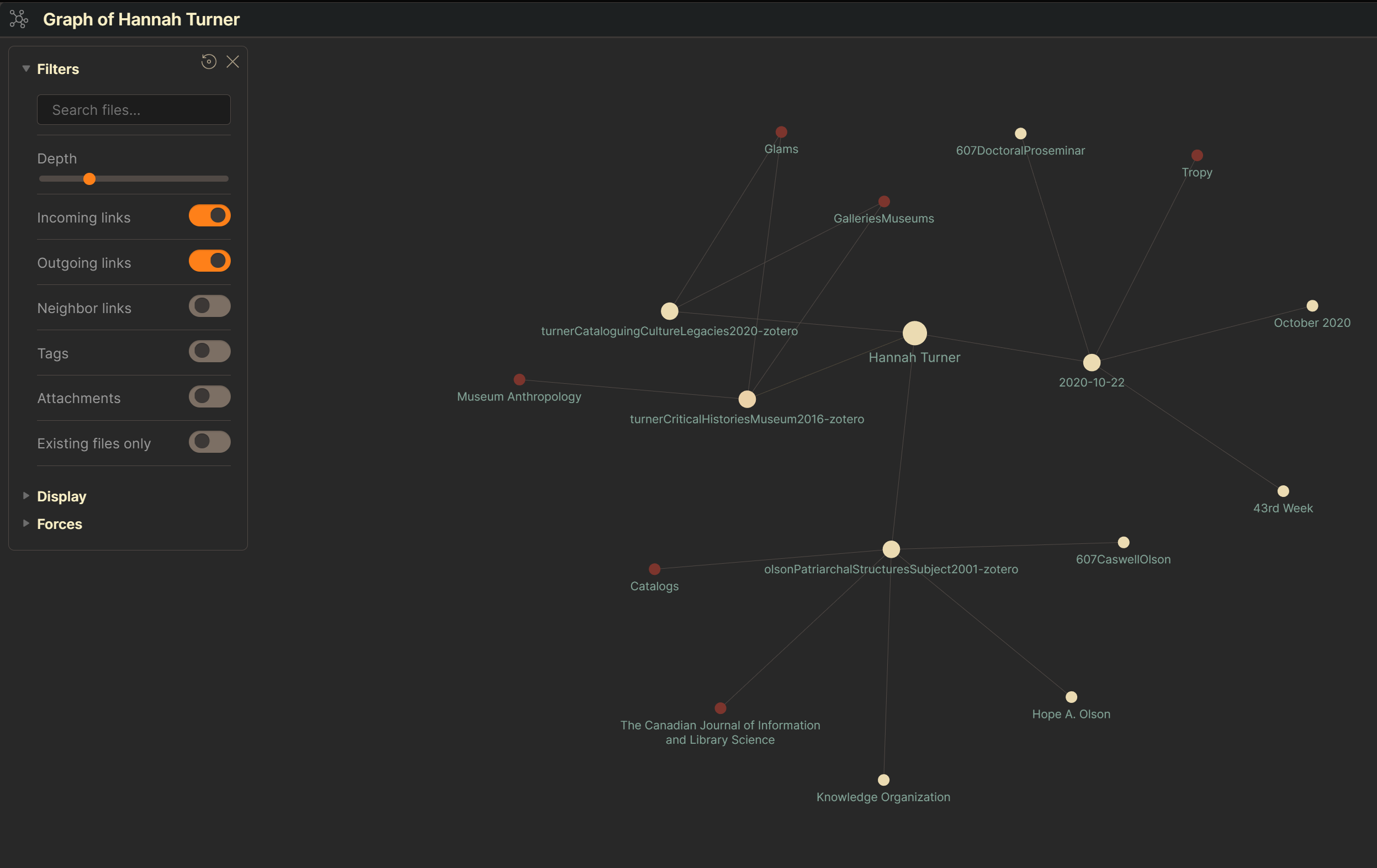
These notes end up in Obsidian where I can examine the graph and see how Hannah Turner has made her way into my academic work:
Universal Decimal and Cutter Classification
- UDC Consortium’s Universal Decimal Classification
- Charles Ammi Cutter’s Expansive Classification
- Nick Milo’s LYT Kit
Anyhow back to those titles.
My favorite classification system is Universal Decimal partially because it can do cool shit like
the sequence of digits is interrupted by a precise type of punctuation sign which indicates that the expression is a combination of classes rather than a simple class e.g. the colon in 34:32 indicates that there are two distinct notational elements: 34 Law. Jurisprudence and 32 Politics; the closing and opening parentheses and double quotes in the following code 913(574.22)“19”(084.3) indicate four separate notational elements: 913 Regional geography, (574.22) North Kazakhstan (Soltüstik Qazaqstan); “19” 20th century and (084.3) Maps (document form)
things can also be coordinated with +, marked as an extension of the first term with /, subgrouped with , specified that it is inclusive with A/Z, and have other systems introduced via *
So searching for “novels about lesbian firefighters in norway from 1960-80 by bisexual authors” is a legit query
I had been trying to force my system into Universal Decimal but kept running against how large and impossibly big the categories it was seeking to describe were. Then I ran into Cutter Classification.
Charles Ammi Cutter was inspired by the decimal classification of his contemporary Melvil Dewey, and with Dewey’s encouragement, developed his own classification scheme for the Winchester Town Library. When he published it, many libraries found this system too detailed and complex for their needs, and Cutter received many requests from librarians at small libraries who wanted the classification adapted for their collections.
The result was the Expansive Classification, a classification system that could be expanded up or down to meet the needs of libraries big to small. Before he died, Cutter completed and published an introduction and schedules for the first six classifications but his work on the seventh was interrupted by his death in 1903. The Library of Congress took the work that he had done and made it into the Library of Congress System.
The first classification looks like this:
For a very small Library
A — Works of reference and works of a general character covering several classes Includes such works as are usually kept in the Delivery Room or the Reading Room for the free use of the public, such as the best dictionaries of languages and other subjects ; encyclopaedias, both general and special, handbooks of dates, dictionaries of biography and peerages, gazetteers, manuals of statistics, books of quotations, concordances, etc.
B — Philosophy and Religion Includes Moral philosophy.
E — Historical sciences Includes Biography, History, and Geography and Travels.
H — Social sciences Includes Statistics, Political Economy, Commerce, the Poor, Charity, Education, Peace, Temperance, the Woman question, Politics, Government, Crime, Legislation, Law.
L — Sciences and Arts, both Useful and Fine
X — Language
Y — Literature Includes Literary history, Bibliography, and the arts that have to do with books.
Yf — Fiction To save time it is not unusual to omit the class-mark of the class Fiction, calling for and charging novels by the book-mark alone.
Taking inspiration from this, was working on a very personalized version of this when I got to talking with Nick Milo.
If you have been paying attention to Nick Milo’s LYT Kit lately you would have noticed a major jump away from Dewey Decimal Classification. Big props to Nick to listening to the concerns raised about Dewey being a racist and sexist bigot terrible even for his time. (Source one, two, three).
After a great chat with Nick we worked together to combine UDC and Cutter classification resulting in the current LYT:
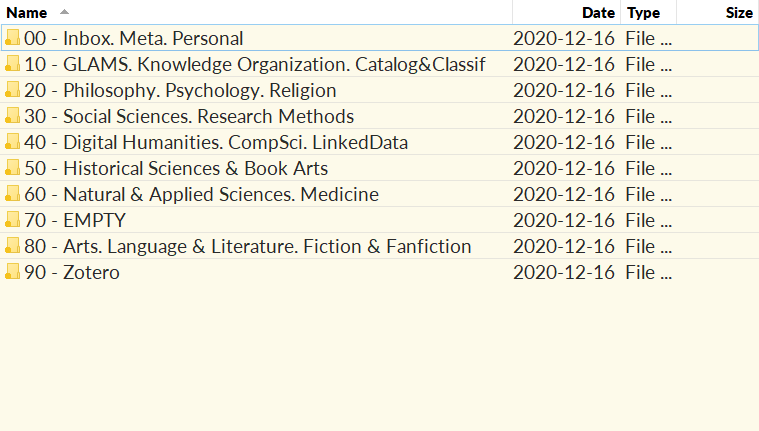
The Self
000 Knowledge Management
100 Personal Management
200 Philosophy & Psychology; Spirituality & Religion
Others
300 Social Sciences
400 Communications & Rhetoric; Language & Linguistics
Others + Self
500 Natural Sciences
600 Applied Sciences
700 Art & Recreation
800 Literature
History of Others & Self
900 History & Biography & Geography
One thing that Nick has been very clear about and that I would be clear about too is that this is a personal knowledge base so you should take these classifications as a starting place and make your own. Which is what I’ve done:
I have a much larger history section than most people so its important to me that it have its own section, like so
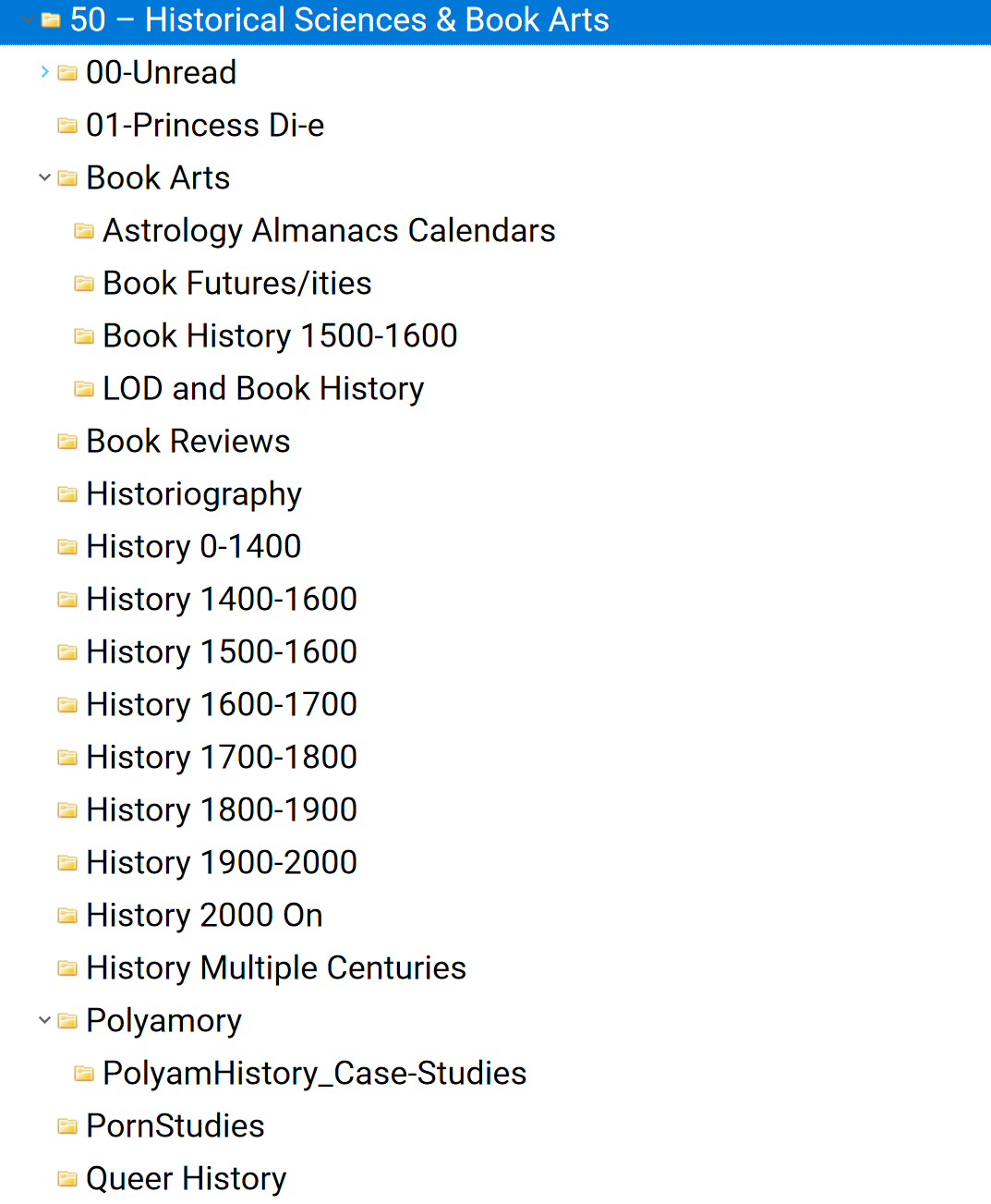
Anyhow! That’s all for now. I hope this is helpful!